Știri

Știri din categoria Inteligență artificială

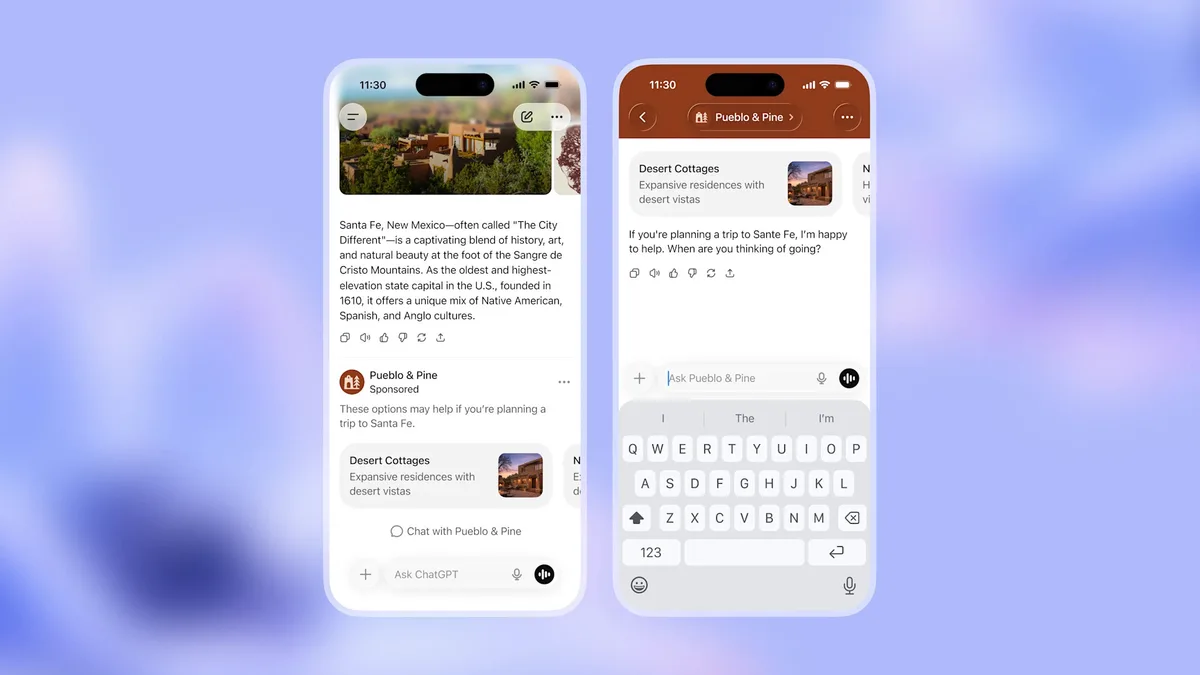
OpenAI va testa reclame în ChatGPT potrivit arstechnica.com, pe fondul presiunilor financiare și al investițiilor masive planificate în infrastructură pentru inteligență artificială. Compania nu se așteaptă să devină profitabilă înainte de 2030 și și-a asumat cheltuieli de aproximativ 1,4 trilioane de dolari pentru centre de date și cipuri.
Conform documentelor financiare obținute în noiembrie de The Wall Street Journal, OpenAI estimează că va „arde” circa 9 miliarde de dolari în 2026, în timp ce ar genera venituri de 13 miliarde de dolari. În același timp, doar aproximativ 5% dintre cei 800 de milioane de utilizatori săptămânali ai ChatGPT plătesc abonamente, ceea ce nu ar acoperi costurile operaționale totale.
Nu toată lumea este convinsă că publicitatea poate rezolva problema. Criticul tech Ed Zitron a scris pe Bluesky că este „extrem de pesimist” în privința produsului de reclame, argumentând că, chiar dacă ar deveni o linie bună de business, costurile serviciilor OpenAI sunt prea mari ca impactul să fie semnificativ.
Inițiativa pare, totodată, în tensiune cu poziții publice anterioare ale CEO-ului Sam Altman, care a vorbit despre un disconfort specific la combinația dintre reclame și inteligență artificială, mai ales dacă presiunea comercială ar ajunge să influențeze răspunsurile chatbotului.
„Când mă gândesc la GPT care îmi scrie un răspuns, dacă ar trebui să mă duc să aflu exact cât din asta e influențat de cine plătește aici ca să influențeze ce mi se arată, nu cred că mi-ar plăcea.”
Din informațiile prezentate, OpenAI încearcă un compromis: reclamele ar urma să fie afișate ca bannere în partea de jos a răspunsurilor, separate de istoricul conversației, pentru a evita apariția conținutului sponsorizat direct în textul generat. Compania susține că ieșirea (răspunsul) asistentului nu va fi influențată de advertiseri.
Din perspectiva utilizatorilor și a eticii, testarea reclamelor ridică o problemă centrală: încrederea că răspunsurile rămân independente și „utile obiectiv”, nu optimizate pentru venituri. Chiar dacă OpenAI promite separarea strictă între publicitate și conținutul generat, simpla introducere a reclamelor poate alimenta suspiciuni privind conflicte de interese, mai ales în situații în care recomandările (produse, servicii, informații) pot avea miză comercială. În acest context, KPI-urile relevante devin nivelul de încredere al utilizatorilor și feedback-ul comunității, care pot indica rapid dacă utilizatorii percep reclamele ca pe o degradare a integrității răspunsurilor sau ca pe un compromis acceptabil pentru finanțarea serviciului.
Recomandate

OpenAI a închis cea mai mare rundă de finanțare din istoria sa , atrăgând 122 mld. dolari la o evaluare de 852 mld. dolari . Tranzacția vine pe fondul așteptărilor din piață că firma ar putea ajunge în 2026 pe piețele publice, iar capitalul nou ar urma să întărească rezervele financiare într-un moment de cheltuieli ridicate pentru infrastructură și talente în inteligență artificială. Runda este condusă de SoftBank împreună cu fondul Andreessen Horowitz , D.E. Shaw Ventures, MGX, TPG și T. Rowe Price, iar Amazon, Nvidia și Microsoft se numără printre investitorii participanți. Publicația mai notează că aproximativ 3 mld. dolari ar proveni de la investitori individuali prin canale bancare. În paralel, OpenAI a anunțat extinderea unei facilități de credit revolving la circa 4,7 mld. dolari, cu sprijinul mai multor bănci globale. Compania spune că linia de credit nu a fost utilizată, iar mesajul transmis este că măsura urmărește flexibilitate financiară în etapa de investiții în putere de calcul și infrastructură, nu acoperirea unui deficit de lichiditate pe termen scurt. Din comunicarea asociată finanțării, OpenAI a publicat și indicatori operaționali și de venituri, într-un registru care, potrivit sursei, seamănă mai degrabă cu o schiță de prospect pentru investitori decât cu o postare obișnuită de blog. Compania afirmă că veniturile lunare au ajuns la 2 mld. dolari și își compară ritmul de creștere cu cel al unor giganți tehnologici. „În această etapă, ritmul nostru de creștere a veniturilor este de patru ori mai mare decât cel al Google, Meta și al altor giganți care au definit era internetului și a mobilului.” Datele prezentate de companie includ și evoluții de produs și monetizare, inclusiv o zonă de publicitate aflată în test, precum și o pondere în creștere a veniturilor din segmentul corporate. OpenAI indică și o accelerare a utilizării funcțiilor de căutare și o extindere a bazei de utilizatori activi și abonați plătitori. Elementele-cheie menționate în materialul sursă sunt: Evaluare: 852 mld. dolari; finanțare atrasă: 122 mld. dolari. Investiții vizate: achiziții de cipuri pentru inteligență artificială, extinderea centrelor de date, recrutare de specialiști. Conducerea rundei: SoftBank, Andreessen Horowitz, D.E. Shaw Ventures, MGX, TPG, T. Rowe Price; participanți: Amazon, Nvidia, Microsoft. Indicatori raportați: venituri lunare de 2 mld. dolari; peste 900 mil. utilizatori activi săptămânal pe zona de consum; peste 50 mil. abonați plătitori; utilizarea căutării aproape s-a dublat în ultimul an; pilotul de publicitate ar fi depășit 100 mil. dolari venit anual recurent în mai puțin de șase săptămâni. Structura veniturilor: segmentul enterprise ar reprezenta 40% (de la circa 30% anul trecut), cu așteptarea de a ajunge la paritate cu zona de consum până la final de 2026. În ansamblu, mesajul transmis de companie prin această rundă și prin modul de prezentare a datelor este că OpenAI își pregătește narativul pentru o eventuală listare, iar finanțarea are rol atât de capitalizare, cât și de ancorare a așteptărilor pieței privind un potențial IPO. [...]

Wikipedia a interzis folosirea inteligenței artificiale pentru generarea sau rescrierea conținutului în enciclopedia sa online, potrivit The Guardian . Decizia vizează în special utilizarea modelelor lingvistice de mari dimensiuni (LLM, sisteme de tip ChatGPT) și se aplică versiunii în limba engleză, care are peste 7,1 milioane de articole. Schimbarea de politică vine după dezbateri în comunitatea de editori voluntari, unde subiectul folosirii AI a fost disputat. Publicația notează că un vot al editorilor a susținut interdicția, conform 404 Media . Wikipedia motivează măsura prin faptul că utilizarea LLM „încalcă adesea” principiile de bază ale proiectului. Totuși, politica introduce două excepții: AI poate fi folosită pentru traduceri și pentru corecturi minore de stil, cu condiția ca un om să verifice rezultatul și ca instrumentul să nu adauge informații noi. „Editorilor li se permite să folosească LLM-uri pentru a sugera corecturi de bază ale propriilor texte și să includă unele dintre ele după o revizuire umană, cu condiția ca LLM-ul să nu introducă conținut propriu”, se arată în noua politică. În același document, Wikipedia avertizează că astfel de modele pot modifica sensul unui text dincolo de cerința inițială și pot ajunge la formulări care nu sunt susținute de sursele citate. Contextul mai larg este creșterea utilizării instrumentelor de AI pentru informare, The Guardian menționând că ChatGPT ar fi depășit Wikipedia la numărul de vizite lunare anul trecut. Articolul amintește și poziții anterioare ale lui Jimmy Wales, fondatorul Wikipedia, care a descris rezultatele înșelătoare sau „halucinate” ale AI drept „un dezastru” și a spus că, deși AI ar putea ajuta în anumite zone, nu ar trebui folosită pentru redactarea articolelor „cel puțin deocamdată”. [...]

Google a început să permită importul de conversații și „memorie” în Gemini din alte aplicații de inteligență artificială, potrivit 9to5Google . Funcția apare odată cu lansarea Gemini 3.1 Flash Live și vizează mutarea contextului din servicii precum ChatGPT și Claude în ecosistemul Gemini. Opțiunea poate fi accesată din interfața Gemini, din meniul „Settings & help” (pictograma rotiță) din colțul stânga-jos, unde apare „Import memory to Gemini”. Utilizatorii sunt trimiși la pagina gemini.google.com/import, care oferă două variante: import de conversații și import de „memorie” (un rezumat structurat al informațiilor despre utilizator). Pentru „Import chats”, utilizatorul exportă datele dintr-o altă aplicație și încarcă în Gemini un fișier.zip de până la 5 GB. Google menționează explicit ChatGPT și Claude și spune că pot fi încărcate până la 5 fișiere.zip pe zi. Pașii indicați pentru export sunt: ChatGPT : numele de utilizator (stânga-jos) → Settings → Data controls → „Export data” → Export → Confirm Export Claude : numele de utilizator (stânga-jos) → Settings → Privacy → „Export data” → Export → selectarea intervalului de date → Export Linkul de descărcare pentru export este trimis pe e-mailul asociat contului de pe platforma respectivă, notează publicația. Conversațiile importate apar în panoul lateral obișnuit din Gemini, dar sunt diferențiate printr-o pictogramă de import. Ele pot fi căutate și șterse individual, iar pentru ștergerea în masă utilizatorul trebuie să găsească intrarea de import și să apese „Delete”, ceea ce elimină toate conversațiile aduse prin acel fișier.zip. Dacă același fișier.zip este încărcat din nou, Gemini adaugă conversațiile noi și suprascrie conversațiile importate anterior. Separat, „Import memory” funcționează prin copierea într-o altă aplicație de chat a unui îndemn (prompt) furnizat de Google, care cere un rezumat al conversațiilor anterioare fără pronume la persoana întâi și a doua, pe categorii precum demografie, interese, relații, evenimente/proiecte și instrucțiuni. Rezultatul este apoi lipit în Gemini. Importul nu este disponibil în prezent în Spațiul Economic European, Elveția sau Regatul Unit, mai arată sursa. [...]

Google a anunțat Gemma 4, o nouă familie de modele AI open-source cu licență Apache 2.0 , potrivit Neowin . Compania spune că modelele sunt construite pe aceeași bază de cercetare ca Gemini 3 (modelele proprietare ale Google), dar, spre deosebire de acestea, Gemma 4 este publicat ca software cu cod sursă deschis și poate fi folosit comercial fără restricții, printr-o licență permisivă. Un element central al generației Gemma 4 este orientarea către „fluxuri de lucru agentice” (agentic workflows), adică scenarii în care un model poate acționa ca un „agent” care execută sarcini și interacționează cu servicii externe. Toate modelele Gemma 4 includ suport nativ pentru apelarea de funcții (function calling), ieșire JSON structurată și instrucțiuni de sistem, ceea ce ar permite dezvoltatorilor să construiască agenți autonomi care rulează local și pot apela API-uri externe. Google își susține poziționarea și cu rezultate din clasamente publice. Conform Google , varianta Gemma 4 „31B Dense” este pe locul 3 între modelele deschise în clasamentul Arena AI, iar modelul „26B” este pe locul 6, compania afirmând că acesta din urmă depășește competitori de până la 20 de ori mai mari ca dimensiune. Tot Google precizează că „greutățile” necuantizate (parametrii modelului, păstrați la precizie mai mare) pentru 26B și 31B încap pe un singur GPU NVIDIA H100 de 80 GB. Pentru dezvoltare locală, articolul notează și existența unui model 26B de tip „Mixture of Experts” (MoE), optimizat pentru latență. În acest tip de arhitectură, nu toți parametrii sunt folosiți la fiecare răspuns; în cazul de față, sunt activați 3,8 miliarde de parametri în timpul inferenței, ceea ce ar crește viteza de generare a tokenilor și ar ajuta la rularea unor asistenți de programare pe plăci grafice de consum. Pe partea de capabilități, Google pune accent și pe multimodalitate: familia Gemma 4 poate procesa nativ imagini și video la rezoluție înaltă, iar modelele „E2B” și „E4B” pentru dispozitive de tip edge (rulare aproape de utilizator, pe hardware local) adaugă intrare audio pentru recunoaștere vocală cu latență foarte mică. În plus, aceste modele vin cu o „fereastră de context” (context window) de 128.000 de tokeni pentru edge și până la 256.000 pentru variantele 26B/31B, adică pot păstra mai multă informație relevantă în aceeași sesiune. Din perspectiva pieței, Google își diferențiază Gemma 4 de iterațiile anterioare, care aveau termeni de utilizare mai restrictivi și erau contestate ca „open-source” în sens strict. Neowin consemnează că, prin licența Apache 2.0 fără limitări comerciale, Google intră mai direct în competiție cu modelele Llama ale Meta, care folosesc, de asemenea, o licențiere de tip Apache. În zona de distribuție și integrare, Gemma 4 este deja compatibil cu platforme precum Hugging Face, Ollama și vLLM și beneficiază de optimizări hardware de la NVIDIA, AMD, Qualcomm și MediaTek. Pentru dezvoltatorii de aplicații mobile, modelele pot fi testate în AICore Developer Preview, Google indicând și compatibilitate viitoare cu Gemini Nano 4. Principalele noutăți menționate pentru Gemma 4: licență Apache 2.0 permisivă, cu utilizare comercială fără restricții; suport nativ pentru function calling, JSON structurat și instrucțiuni de sistem (orientare către agenți AI); modele 26B/31B care, potrivit Google, încap ca „greutăți” necuantizate pe un GPU NVIDIA H100 de 80 GB; variantă 26B MoE optimizată pentru latență, cu 3,8 miliarde de parametri activați la inferență; multimodalitate (imagini/video), plus intrare audio pe modelele edge E2B/E4B; ferestre de context de 128K tokeni (edge) și până la 256K (26B/31B). [...]

Astera Labs a anunțat că s-a alăturat Arm Total Design pentru a accelera soluțiile personalizate de infrastructură AI. Potrivit Astera Labs , această colaborare vizează cerințele tot mai mari ale infrastructurii la scară de rack, prin arhitecturi de chiplet personalizate pentru conectivitate. Astera Labs, cunoscută pentru soluțiile sale de conectivitate bazate pe semiconductori, va combina ecosistemul său Intelligent Connectivity Platform cu Arm Neoverse Compute Subsystems (CSS). Această integrare va permite dezvoltarea de soluții chiplet care să răspundă cerințelor crescânde ale infrastructurii AI personalizate. De asemenea, abordarea modulară propusă va facilita o lansare mai rapidă pe piață, prin componente validate și reutilizabile. Importanța arhitecturilor chiplet Arhitecturile chiplet devin tot mai relevante pe măsură ce sarcinile de lucru AI necesită capacități de procesare specializate. Designurile tradiționale de cipuri monolitice întâmpină limitări de randament și costuri la noduri de proces avansate. Astfel, arhitecturile chiplet permit dezvoltatorilor de platforme AI să combine unități de procesare diverse, inclusiv subsisteme de calcul Arm, alături de componente de memorie, rețea și accelerare. Astera Labs va oferi capabilități multi-protocol prin platforma sa de conectivitate inteligentă, incluzând soluții de conectivitate PCIe, Ethernet, CXL și UALink. Acestea vor permite clienților să construiască infrastructuri AI personalizate, cu conectivitate validată și interoperabilă încă din prima zi. Colaborarea cu Arm și beneficiile sale Colaborarea cu Arm va combina expertiza în subsisteme de calcul cu leadership-ul Astera Labs în conectivitate. Aceasta are ca scop accelerarea timpului de lansare pe piață și suportul pentru platforme bazate pe standarde deschise, care valorifică inovația largă și lanțurile de aprovizionare multi-vendor. „Evoluția către infrastructura AI la scară de rack necesită soluții personalizate dezvoltate în cadrul unor ecosisteme deschise, iar colaborarea noastră cu Arm exemplifică această abordare,” a declarat Sanjay Gajendra, președintele și directorul operațional al Astera Labs. Mohamed Awad, vicepreședinte senior și director general al Arm, a subliniat importanța conectivității în realizarea potențialului complet al sistemelor integrate și în satisfacerea cerințelor de putere și performanță ale AI. Perspective și provocări Prin Arm Total Design, clienții vor avea acces la un ecosistem cuprinzător care combină expertiza în conectivitate a Astera Labs cu subsistemele de calcul ale Arm. Aceasta poziționează companiile pentru a profita de piața în expansiune rapidă a infrastructurii AI personalizate. Cu toate acestea, există riscuri și incertitudini legate de succesul combinării platformei de conectivitate a Astera Labs cu produsele Neoverse CSS ale Arm. Printre acestea se numără provocările tehnologice, condițiile macroeconomice și restricțiile de reglementare, care ar putea afecta rezultatele așteptate ale colaborării. [...]

AMD a anunțat că evenimentul „Advancing AI 2026” va avea loc pe 22-23 iulie , potrivit Wccftech . Conferința este programată la Moscone Center din San Francisco și va include un discurs principal susținut de directoarea generală a companiei, Dr. Lisa Su, alături de prezentări ale unor executivi AMD și invitați din ecosistem. Evenimentul este prezentat de AMD drept întâlnirea anuală a comunității globale de inteligență artificială, unde dezvoltatori, clienți și parteneri discută infrastructura, arhitectura și instrumentele de dezvoltare pentru implementarea și scalarea sistemelor de AI în mediul de întreprindere și în cloud. Publicația amintește că, la ediția anterioară, AMD a folosit scena „Advancing AI” pentru a prezenta acceleratoarele din seria MI350, platforma software ROCm 7 (ecosistemul AMD pentru dezvoltare și rulare de aplicații AI pe hardware-ul companiei) și un prim indiciu despre rack-ul Helios, care ar urma să includă procesoare EPYC Venice („Zen 6”) și infrastructură Pensando. Pentru 2026, Wccftech anticipează că AMD va pune accent pe tehnologiile de AI pentru segmentul enterprise, inclusiv acceleratoarele Instinct din seria MI450 și procesoarele EPYC Venice („Zen 6”), despre care compania a discutat deja în cadrul unui eveniment pentru analiști financiari. În acest context, publicația sugerează că AMD ar putea folosi conferința nu doar pentru a detalia planurile de produs pentru 2026, ci și pentru a oferi indicii despre generațiile următoare. În plus, articolul leagă calendarul „Advancing AI 2026” de Computex 2026, care are loc cu puțin peste o lună înainte, unde AMD ar putea prezenta noutăți pentru piața de consum, inclusiv un posibil prim indiciu despre viitoarea generație de procesoare Ryzen și actualizări pentru laptopuri. Detaliile oficiale despre eveniment sunt disponibile și pe site-ul AMD, menționează Wccftech. [...]

