Știri

Știri din categoria Inteligență artificială

Google negociază cu Pentagonul rularea TPU-urilor în medii clasificate, un pas care ar putea reduce decalajul față de AWS și Microsoft pe contractele guvernamentale, potrivit Tom's Hardware, care citează un material The Information bazat pe două persoane cu informații directe despre discuții.
Negocierile vizează implementarea modelului Gemini în setări clasificate ale Departamentului Apărării al SUA (DoD) și includ două direcții: adăugarea de rack-uri cu GPU-uri (procesoare grafice folosite frecvent pentru sarcini de inteligență artificială) în Google Distributed Cloud și, în paralel, activarea TPU-urilor (acceleratoarele AI dezvoltate de Google) în medii clasificate acreditate. Conform sursei, ar fi prima dată când TPU-urile ar rula într-un astfel de cadru.
Din perspectiva Google, discuțiile au o miză comercială și operațională: compania are aproximativ 14% din piața totală de cloud, față de 28% pentru AWS și 21% pentru Microsoft, conform Synergy Research Group (date „la final de 2025”, citate în articol). Diferența ar fi și mai mare în zona de cloud pentru medii clasificate, unde rivalii rulează deja volume importante de lucru, iar Google nu.
În acest context, divizia Google Public Sector, care conduce discuțiile cu DoD, ar fi vizat circa 6 miliarde de dolari (aprox. 27,6 miliarde lei) în „bookings” pentru 2025–2027, din care 2 miliarde de dolari (aprox. 9,2 miliarde lei) din apărare, potrivit unui plan strategic intern pe care The Information spune că l-a văzut.
Un element central al negocierilor este limbajul contractual. Propunerea ar permite Pentagonului să folosească Gemini pentru „toate scopurile legale”, însă Google ar insista pentru prevederi care să interzică:
Tom’s Hardware notează că aceste condiții ar oglindi acordul pe care OpenAI l-a încheiat cu Pentagonul mai devreme în acest an, iar directorul general al OpenAI, Sam Altman, ar fi cerut Pentagonului să extindă aceleași condiții către toți furnizorii de AI.
Aceleași teme ar fi stat la baza ruperii negocierilor Pentagonului cu Anthropic în februarie, după ce compania ar fi refuzat să renunțe la restricții. Ulterior, Pentagonul ar fi desemnat Anthropic drept „risc de lanț de aprovizionare” și ar fi început eliminarea treptată, pe șase luni, a modelului Claude din sistemele guvernamentale. Un judecător federal ar fi descris ulterior această etichetare drept „orwelliană”, potrivit articolului.
Materialul nu indică un calendar sau un rezultat al negocierilor și nici detalii despre forma finală a contractului. Cert este că, dacă TPU-urile ajung să fie operate în medii clasificate acreditate, Google ar bifa o capabilitate pe care o folosește deja masiv în cloud-ul comercial pentru antrenarea și rularea (inferența) Gemini, dar pe care nu a avut-o până acum în segmentul guvernamental clasificat.
Recomandate

Google extinde Google Vids cu Gemini Omni și avatare personale, mutând editarea video spre comenzi în limbaj natural și conținut generat cu marcaj de transparență , potrivit Google Blog . Actualizările vizează reducerea timpului și a efortului necesare pentru a produce clipuri „de calitate” în mediul de lucru, inclusiv fără filmare clasică. Ce se schimbă operațional în Google Vids Google introduce două funcții noi în Google Vids: Gemini Omni , care permite generarea și editarea video din text și imagini . Utilizatorul pornește de la un „prompt” (instrucțiune scrisă în limbaj obișnuit) și poate adăuga referințe vizuale, precum o fotografie sau o schiță, pentru a ghida rezultatul. Editare prin conversație, pas cu pas : utilizatorii pot cere modificări incremental (de exemplu, schimbarea fundalului, ajustarea luminii sau adăugarea de efecte) fără să reia proiectul de la zero, inclusiv pentru clipuri filmate cu telefonul. Avatare personale , care permit „prezența” în video fără cameră: utilizatorul încarcă un selfie și o scurtă înregistrare vocală, apoi tastează mesajul, iar avatarul îl livrează. Cine are acces și ce limitări există Funcțiile Gemini Omni și avatarele personale sunt disponibile în Google Vids pentru: abonații Google AI Pro și Ultra ; clienții Google Workspace pentru business. Accesul la avatare personale este, deocamdată, limitat la anumite regiuni și doar pentru utilizatori de 18 ani sau mai mult . Avatarele sunt legate de contul Google al utilizatorului și sunt restricționate la „asemănarea” titularului contului, conform descrierii din material. Transparentizarea conținutului generat cu AI Google spune că fiecare clip generat include un watermark digital invizibil SynthID , menit să permită verificarea faptului că un video a fost creat cu inteligență artificială. Miza practică pentru companii este reducerea riscului de confuzie privind originea conținutului, într-un context în care materialele video generate devin mai ușor de produs și distribuit. Context: accelerarea producției video în Vids Google afirmă că, în ultimul an, utilizatorii au creat „milioane” de videoclipuri în Google Vids și amintește că, în februarie, a extins către toți utilizatorii integrarea Veo 3.1 pentru generare video în Vids. Noile funcții împing mai departe aceeași direcție: producție și editare video ghidate prin instrucțiuni text, cu personalizare la nivel de „prezentator” digital. [...]
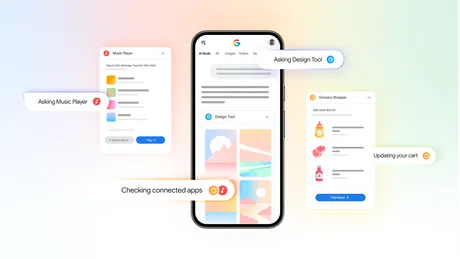
Google extinde „aplicațiile conectate” în AI Mode din Căutare, permițând utilizatorilor să lege servicii externe și să execute acțiuni direct din rezultate . Potrivit Google Blog , funcția începe să fie disponibilă „în această săptămână” în SUA, iar integrarea este gândită ca utilizatorii să poată interacționa „în siguranță” cu serviciile preferate fără să iasă din fluxul de căutare. Ce se schimbă operațional în Căutare Noutatea este că legarea aplicațiilor nu mai este limitată la aplicația Gemini, ci ajunge direct în Search, în AI Mode (modul de căutare asistat de inteligență artificială). Odată conectate, aceste servicii pot fi folosite pentru a duce la capăt sarcini concrete din răspunsurile generate. Google descrie câteva scenarii de utilizare: Instacart : utilizatorul poate adăuga ingredientele dintr-o listă de cumpărături direct în coșul Instacart și poate finaliza comanda cu câteva atingeri în aplicație sau pe site. Canva : utilizatorul poate cere sugestii de șabloane (de exemplu, pentru un fluturaș) direct din AI Mode. YouTube Music : utilizatorul poate crea o listă de redare și o poate salva instant în YouTube Music pentru redare. Cine poate folosi și când Google spune că funcția începe să fie implementată în această săptămână în SUA . Publicația nu oferă un calendar pentru extinderea în alte țări și nici o listă completă de parteneri disponibili la lansare, menționând doar că lucrează cu „o gamă” de parteneri și că vor urma și alte aplicații. Unde găsești opțiunea și ce înseamnă „aplicații conectate” Utilizatorii sunt direcționați către AI Mode din Search pentru a încerca „ connected apps ” (aplicații conectate). Google pune la dispoziție și o pagină de suport pentru funcție: connected apps , respectiv pagina AI Mode: AI Mode . În același context, compania reamintește că utilizarea datelor se face conform politicii sale de confidențialitate: Google’s privacy policy . [...]

Google și Screwfix duc instruirea practică în AI direct în magazine, pentru a reduce „decalajul de ghidaj” care îi împiedică pe meseriașii din Marea Britanie să obțină valoare reală din instrumentele de inteligență artificială , potrivit Google Blog . Parteneriatul vizează lucrătorii din construcții și alte meserii (constructori, instalatori, electricieni), într-un context în care utilizarea AI este deja ridicată: 86% dintre muncitorii din construcții folosesc AI la job. Totuși, datele citate de Google indică o problemă operațională: 71% vor să învețe mai mult, dar 54% nu știu la cine să apeleze, iar doar 16% spun că scot „valoare semnificativă” din aceste instrumente. Ce se schimbă, concret Google spune că va livra „sfaturi rapide și practice” în magazinele Screwfix din toată țara, pentru a ajuta meseriașii să folosească mai eficient instrumentele AI pe care „deja le au în buzunar” (în practică, aplicații și servicii accesibile pe telefon). Inițiativa este anunțată ca una națională, cu exemple de acoperire „de la Newcastle la Belfast”. La ce ar urma să fie folosită AI în activitatea de zi cu zi Exemplele de utilizare menționate în material sunt orientate spre reducerea timpului pierdut cu sarcini administrative și accelerarea livrării către client, inclusiv: transformarea notițelor scrise de mână în propuneri/ofertări pentru clienți; transformarea schițelor sumare în randări 3D. Google leagă explicit eficientizarea acestor activități de potențialul de creștere al micilor afaceri și, indirect, de efecte pozitive la nivelul economiei britanice. Unde pot găsi companiile informații suplimentare Cei interesați sunt trimiși către platforma grow.google pentru resurse despre folosirea AI în afaceri. Pentru context suplimentar despre inițiativele Google din Marea Britanie, compania indică și un material despre programe de dezvoltare a competențelor AI („ level up their AI skills ”) disponibil aici . [...]

România riscă o polarizare a economiei pe fondul adopției „informale” a inteligenței artificiale , în condițiile în care utilizarea reală în companii pare mult peste statisticile oficiale, dar fără competențe digitale suficiente și fără sprijin sistematic pentru tranziție, potrivit unei analize citate de Economedia . Analiza „AI – impact pe piața muncii: index de poziționare la nivel european”, realizată de IMM România , plasează România în categoria „decalaj semnificativ” față de media UE-27 în pregătirea pieței muncii pentru inteligența artificială. Țara are un index final de 52,5 din 100 (unde 100 reprezintă media UE-27), sub toate statele din grupul regional de comparație: Cehia (92,1), Ungaria (77,1), Polonia (74,8) și Bulgaria (59,9), și mult sub Estonia (106,1), indicată ca reper de bune practici. Adopția crește, dar decalajul față de UE rămâne Între 2021 și 2025, adopția IA în firmele românești cu peste 10 angajați a crescut de peste trei ori, de la 1,4% la 5,2%. În același interval, media europeană a urcat de la 7,7% la aproape 20%, menținând un raport de aproximativ unu la patru. Concluzia analizei este că, fără intervenții țintite, România riscă să rămână permanent în urmă. În plus, IMM România susține că adopția reală depășește semnificativ datele oficiale: într-un sondaj propriu, 66,1% dintre firmele respondente declară că folosesc deja cel puțin un instrument de tip IA, față de 5,2% cât indică statistica oficială pentru companiile cu peste 10 angajați. Vulnerabilitatea majoră: competențe digitale și inovare slabă Analiza indică drept punct cel mai vulnerabil pilonul de inovare și adaptare instituțională, cu un scor de 20,5, asociat cu cel mai redus nivel al cheltuielilor de cercetare-dezvoltare din Uniunea Europeană. Pe zona de capital uman, doar 31,8% dintre români au competențe digitale cel puțin de bază, față de 60,4% media UE, ceea ce plasează România la cel mai redus nivel din Uniune. În acest context, IMM România avertizează asupra unei distribuții inegale a capacității de adaptare: un nucleu de firme și angajați avansează rapid, în timp ce microîntreprinderile și lucrătorii din sectoare tradiționale (comerț, transport, HoReCa, industrie) rămân expuși, fără mijloace de tranziție. Ce măsuri cere IMM România și legătura cu AI Act (2026–2027) Florin Jianu, președintele IMM România, spune că viteza de adopție „pe cont propriu” poate accentua polarizarea dacă nu este susținută prin politici publice și programe de formare. „Datele ne arată un paradox: antreprenorii români adoptă inteligența artificială mult mai repede decât o vede statistica oficială, dar o fac pe cont propriu, fără sprijin, fără ghiduri și fără competențele de bază extinse în forța de muncă. Miza următorilor doi ani nu este dacă IA va transforma piața muncii din România, pentru că o face deja, ci dacă vom lăsa această transformare să polarizeze economia sau o vom transforma într-o oportunitate pentru toate firmele, inclusiv pentru IMM-uri.” IMM România solicită, între altele: operaționalizarea unui Program național de alfabetizare IA pentru forța de muncă, sub forma unor vouchere de formare pentru IMM-uri și angajați; programe active de reconversie prin partenerii sociali, orientate către sectoare cu expunere ridicată și capacitate redusă de absorbție; pregătirea din timp pentru termenele de aplicare 2026–2027 ale AI Act (regulamentul UE privind inteligența artificială). Analiza este construită pe nouă indicatori oficiali Eurostat , grupați în patru piloni (capital uman digital, digitalizarea firmelor, structura ocupării și inovare) și este completată de un sondaj realizat în rândul a 463 de IMM-uri. [...]

Honor vrea să păstreze butonul fizic de AI pe seria Magic 9 , dar îl repoziționează pentru a reduce apăsările accidentale , potrivit Huawei Central . Informația indică o ajustare de design cu impact direct în utilizare: compania încearcă să facă butonul mai accesibil, după plângeri legate de poziționarea lui pe generația anterioară. Un „tipster” (persoană care publică neoficial informații despre produse) de pe Weibo, , susține că Honor va păstra un buton mic pe lateralul telefoanelor Magic 9 pentru acces rapid la anumite funcții, la fel ca pe modelele din seria Magic 8. Diferența ar fi poziția: nu ar mai fi neapărat sub butoanele de pornire și volum, ci ar putea fi mutat pe o altă latură a telefonului. De ce contează: butonul de AI a fost criticat pentru ergonomie Honor a introdus butonul fizic de AI anul trecut, odată cu seria Magic 8. Conform descrierii din material, apăsarea lungă pornește asistentul YOYO și duce utilizatorul direct către sarcini, iar dublu-tap poate deschide camera sau alte aplicații. Totuși, o parte dintre utilizatorii Magic 8 au reclamat că butonul este poziționat prost și poate fi apăsat accidental. În acest context, repoziționarea devine o schimbare operațională importantă: dacă butonul rămâne o componentă centrală a interacțiunii cu funcțiile de inteligență artificială, ergonomia lui poate influența direct cât de des este folosit (sau dezactivat/evitat). „Capcana”: poziția nouă nu este încă dezvăluită Sursa notează că tipsterul nu a indicat unde va fi mutat butonul, ci doar că Honor „optimizează” poziția pentru accesibilitate. Asta înseamnă că, deocamdată, schimbarea rămâne la nivel de informație neoficială și fără detalii de implementare. În paralel, materialul menționează că seria Magic 9 ar urma să includă și funcții din AgenticOS (un set de capabilități care ar crește „operabilitatea” butonului de AI), precum și upgrade-uri pentru agentul virtual YOYO în MagicOS 11. Detaliile despre ce anume va primi seria Magic 9 și cum va fi folosit butonul în aceste scenarii ar urma să devină mai clare pe măsură ce se apropie lansarea. [...]

Apple își întărește capacitățile de IA pentru China prin recrutarea echipei inițiale din spatele versiunii open-source a modelului Qwen , într-o mișcare care ar putea accelera adaptarea Siri la piața chineză și la constrângerile locale privind modelele și serviciile de inteligență artificială, potrivit Wccftech . Informația este atribuită analistului de IA Robert Scoble (fost Microsoft), iar publicația precizează că nu există o confirmare independentă. Totuși, în contextul în care Apple își adâncește parteneriatul cu Alibaba, recrutarea ar avea logică operațională: compania ar câștiga expertiză directă pe un model care urmează să fie pus la dispoziția utilizatorilor din China în cadrul „Apple Intelligence”. De ce contează: Siri în China depinde de parteneriate și execuție locală Apple a început să ofere utilizatorilor din China acces la familia de modele Qwen de la Alibaba prin interfața Apple Intelligence, într-un mod pe care Wccftech îl compară cu integrarea actuală a ChatGPT în ecosistemul Apple. Un purtător de cuvânt Alibaba a descris integrarea ca permițând accesul la capabilități precum „înțelegerea și generarea de text și imagini”, fără a comuta între instrumente. În acest cadru, aducerea „echipei originale” care a lucrat la versiunea open-source a Qwen ar putea reduce timpul de integrare și ajustare a funcțiilor Siri pentru limba, datele și cerințele pieței locale, unde Apple nu poate replica integral abordarea din SUA sau UE. Context: Apple își reconstruiește Siri și o împinge mai adânc în interfața iPhone Materialul notează că noua versiune Siri este integrată în Dynamic Island, are acces la „context personalizat” și poate folosi informații de pe ecran. Sunt oferite exemple de utilizare: întrebări despre un concert urmate de adăugarea datei în Reminders prin comandă vocală, identificarea conținutului unei imagini și furnizarea de context personalizat (de tipul unei persoane care locuiește lângă un parc), inclusiv indicații către o adresă. Ce urmează: Qwen3.8 și presiunea de a livra rapid În paralel, Alibaba pregătește lansarea modelului Qwen3.8 „destul de curând”, potrivit sursei. Wccftech sugerează că noua versiune ar ridica miza în competiția dintre modelele „open-source/open-weight” (modele cu greutăți publice, reutilizabile), ceea ce ar putea pune presiune pe Apple să țină pasul cu ritmul de actualizare al partenerului său din China. Separat, articolul amintește că Financial Times a relatat despre demersuri de lobby ale Apple pentru aprobarea achiziției de DRAM de la CXMT (aflată pe o listă a Pentagonului), iar Bloomberg, prin Mark Gurman, a scris că Apple ar lucra cu administrația Trump pentru a limita reacțiile negative din Washington dacă ajunge să cumpere memorie de la CXMT și YMTC pentru produse vândute în China. Aceste elemente conturează o strategie mai amplă: Apple încearcă să-și securizeze atât „motorul” hardware, cât și „creierul” software pentru operațiunile din China, într-un mediu geopolitic și de reglementare mai dificil. [...]


