Știri

Știri din categoria Inteligență artificială

Google își accelerează strategia de a reduce dependența de Nvidia prin discuții cu Marvell Technology pentru dezvoltarea a două cipuri dedicate inteligenței artificiale, într-un demers care ar putea influența costurile și capacitatea de livrare a Google Cloud, potrivit ITmedia.
Informația, atribuită de ITmedia publicației The Information, indică negocieri între Google (parte a Alphabet) și Marvell pentru a crea două componente noi menite să ruleze mai eficient modele de inteligență artificială. Miza este dublă: performanță mai bună pentru sarcini AI și o alternativă mai credibilă la plăcile grafice (GPU) Nvidia, care domină infrastructura de antrenare și inferență pentru AI.
Potrivit materialului, proiectul ar include:
ITmedia notează că Google lucrează de mai mult timp la poziționarea TPU ca alternativă viabilă la GPU-urile Nvidia folosite pe scară largă în industrie.
Articolul leagă direct această inițiativă de presiunea asupra Google de a demonstra investitorilor că investițiile în AI se transformă în rezultate comerciale. În acest context, vânzările de TPU sunt prezentate ca un factor important pentru creșterea veniturilor din Google Cloud.
Cu alte cuvinte, dacă Google reușește să-și întărească oferta de cipuri proprii (și ecosistemul din jurul lor), poate câștiga atât la nivel de costuri și disponibilitate a infrastructurii, cât și la nivel de diferențiere față de competitori care depind mai mult de Nvidia.
Conform informațiilor citate, cele două companii ar urmări ca proiectarea unității de procesare a memoriei să fie finalizată cel mai devreme anul viitor, după care ar urma livrarea pentru producție de test.
Materialul nu oferă detalii despre termeni comerciali, volume sau despre momentul în care noul TPU ar putea intra în producție.
Recomandate

Google mizează pe modele Gemini mai ieftine și mai rapide pentru „agenți” AI, în timp ce versiunea de vârf Pro întârzie , potrivit TechCrunch . Google DeepMind a lansat marți trei modele noi — Gemini 3.6 Flash, 3.5 Flash-Lite și 3.5 Flash Cyber — cu accent pe eficiență, latență și fiabilitate pentru clienții care rulează agenți AI la scară. Gemini 3.6 Flash este descris de Google drept „modelul de lucru” și promite îmbunătățiri la programare, activități de tip „knowledge work” și performanță multimodală, reducând în același timp consumul de „tokeni” (unități folosite la calculul costurilor și al volumului de text procesat) cu până la 17% față de 3.5 Flash — ceea ce ar trebui să îl facă mai ieftin în utilizare. Gemini 3.5 Flash-Lite este poziționat ca cel mai rentabil model din clasă, iar 3.5 Flash Cyber este o variantă specializată, ajustată pentru identificarea și remedierea vulnerabilităților de securitate cibernetică. Pentru acesta din urmă, Google spune că accesul va fi limitat inițial: modelul va fi disponibil exclusiv guvernelor și „partenerilor de încredere”, într-un program pilot cu acces restrâns. De ce contează: eficiență operațională acum, „Pro” mai târziu Lansarea e relevantă nu doar prin faptul că Google livrează modele mai ieftine și optimizate pentru producție, ci și prin absența unei actualizări pentru Gemini Pro, modelul de vârf al companiei pentru sarcini complexe de raționament și programare. Pro a fost actualizat ultima dată în februarie, iar între timp rivalii au accelerat ritmul: OpenAI a lansat GPT-5.5 și a început să extindă accesul la GPT-5.6, iar Anthropic a venit cu Claude Opus 4.8 și Claude Sonnet 5 și a extins accesul la modelul Fable 5, notează publicația. Google sugerase în mai că versiunea Pro „era deja folosită intern” și că urmează să fie lansată „luna viitoare”. Săptămâna trecută, Bloomberg a relatat că lansarea Gemini 3.5 Pro a fost întârziată din cauza dificultății de a atinge ținte interne de performanță. Ce urmează: testare cu parteneri și pregătiri pentru Gemini 4 Liderul de produs Google DeepMind, Logan Kilpatrick , a declarat marți că Google testează în prezent Gemini 3.5 Pro cu parteneri și speră să îl „lanseze în curând”. Tot el a spus că echipa a început „cea mai ambițioasă rundă de pre-antrenare de până acum” pentru Gemini 4 — un indiciu că Google încearcă să recupereze teren atât prin optimizări de cost și viteză, cât și printr-o nouă generație de modele. [...]

O geacă purtată de Jensen Huang a fost adjudecată cu 960.000 de dolari (aprox. 4,4 milioane lei), un semnal despre cât de departe a ajuns „economia de colecție” din jurul boomului AI , potrivit Gizmodo . Este vorba despre o geacă de piele Tom Ford, vândută prin Sotheby’s , despre care publicația spune că a fost purtată de CEO-ul Nvidia la un eveniment Foxconn din 2023. Ce s-a vândut și cine a confirmat tranzacția Articolul indică faptul că piesa a apărut într-o listare online Sotheby’s și că detalii vizuale (fermoare diagonale) ar corespunde cu geaca purtată de Huang într-un clip de la evenimentul din 2023. Nu sunt oferite detalii despre cumpărător. Brahm Wachter, care conduce o divizie Sotheby’s numită „modern collectibles” (colecționabile moderne), a declarat pentru CNBC că „răspunsul la această vânzare a depășit chiar și cele mai mari așteptări”. În textul Gizmodo, declarația este folosită ca indiciu că prețul a surprins inclusiv casa de licitații. De ce contează economic: „merch” de AI tratat ca activ de statut Miza, dincolo de excentricitatea tranzacției, este normalizarea ideii că obiecte asociate cu lideri ai industriei AI pot fi tranzacționate ca bunuri de prestigiu, comparabile cu alte simboluri de statut. Gizmodo notează că cineva a plătit o sumă „care îți schimbă viața” pentru o piesă vestimentară devenită marcă personală a lui Huang, sugerând o apropiere de logica piețelor de colecție și de „memorabilia” din jurul unor fenomene culturale. Publicația plasează episodul în contextul rolului lui Jensen Huang în „povestea AI a anilor 2020”, argumentând că geaca a ajuns să fie percepută drept un artefact al perioadei. Ce nu se știe și ce urmează Nu există informații în material despre identitatea cumpărătorului, motivația exactă a achiziției sau despre o eventuală revânzare. În lipsa acestor date, rămâne doar concluzia practică: piața de colecționabile începe să monetizeze direct simbolurile vizuale ale boomului AI, iar astfel de tranzacții pot încuraja apariția unei nișe de „memorabilia” legată de liderii și momentele-cheie ale industriei. [...]

Japonia își construiește o infrastructură națională de „fabrici AI” pentru aplicații industriale , mizând pe o capacitate de centru de date de 140 MW și pe acces mai larg la modele de bază (foundation models) pentru companii și dezvoltatori locali, potrivit NVIDIA News . Inițiativa este susținută de Ministerul Economiei, Comerțului și Industriei din Japonia (METI) și este prezentată drept „prima infrastructură națională de inteligență artificială” dedicată „ physical AI ” (aplicații care conectează AI cu lumea fizică, precum robotică și automatizare). NVIDIA va lucra cu Noetra Corp. pentru a lansa o „AI factory” bazată pe platforma NVIDIA DSX, cu 13.750 procesoare Vera (CPU) și 27.500 procesoare grafice Rubin (GPU). Ce se construiește și la ce va fi folosit Noua „fabrică AI”, înființată de Noetra, va fi proiectată cu rack-uri NVIDIA Vera Rubin NVL72 , folosind platforma NVIDIA DSX și rețelistică NVIDIA Spectrum-X Ethernet. Scopul operațional declarat este dezvoltarea de modele multimodale deschise (care pot combina mai multe tipuri de date, de exemplu text, imagini și semnale din senzori) pentru: agenți AI (software care poate executa sarcini în mod autonom), „digital twins” (replici digitale ale unor procese/echipamente reale), robotică, alte aplicații de „physical AI”. FRONTia, proiectul guvernamental care primește baza de calcul Infrastructura va furniza „fundația de calcul” pentru proiectul FRONTia al METI („Development of Multimodal Foundation Models with a View to AI Robotics and Physical AI”). Conform sursei, proiectul urmărește să combine expertiza industrială a Japoniei, date industriale din lumea reală și parteneri tehnologici globali pentru a dezvolta modele multimodale „foarte fiabile” pentru aplicații fizice. Un element cu impact direct pentru ecosistemul local: Noetra va face disponibile pe scară largă „greutățile” (weights) pre-antrenate ale modelelor sale multimodale către dezvoltatori de modele și companii din Japonia, împreună cu software NVIDIA (inclusiv Nemotron, Cosmos, Isaac GR00T și biblioteci NeMo). De ce contează economic: legătura cu piața de robotică AI Anunțul este aliniat cu strategia Japoniei în robotică: „AI Robotics Strategy”, publicată în martie, își propune ca Japonia să capteze peste 30% din piața globală de robotică AI până în 2040, o oportunitate estimată la 133 miliarde dolari (aprox. 610 miliarde lei), potrivit sursei. În acest context, infrastructura de calcul și accesul la modele de bază sunt prezentate ca pârghii pentru accelerarea aplicațiilor în industrie (producție, logistică, sănătate, telecomunicații). Pe măsură ce „fabrica AI” se extinde, aceasta ar urma să susțină antrenarea unor modele la scară de trilioane de parametri, oferind organizațiilor din Japonia acces la un mediu avansat pentru dezvoltarea următoarei generații de aplicații în producție inteligentă și robotică. [...]

Google extinde Google Vids cu Gemini Omni și avatare personale, mutând editarea video spre comenzi în limbaj natural și conținut generat cu marcaj de transparență , potrivit Google Blog . Actualizările vizează reducerea timpului și a efortului necesare pentru a produce clipuri „de calitate” în mediul de lucru, inclusiv fără filmare clasică. Ce se schimbă operațional în Google Vids Google introduce două funcții noi în Google Vids: Gemini Omni , care permite generarea și editarea video din text și imagini . Utilizatorul pornește de la un „prompt” (instrucțiune scrisă în limbaj obișnuit) și poate adăuga referințe vizuale, precum o fotografie sau o schiță, pentru a ghida rezultatul. Editare prin conversație, pas cu pas : utilizatorii pot cere modificări incremental (de exemplu, schimbarea fundalului, ajustarea luminii sau adăugarea de efecte) fără să reia proiectul de la zero, inclusiv pentru clipuri filmate cu telefonul. Avatare personale , care permit „prezența” în video fără cameră: utilizatorul încarcă un selfie și o scurtă înregistrare vocală, apoi tastează mesajul, iar avatarul îl livrează. Cine are acces și ce limitări există Funcțiile Gemini Omni și avatarele personale sunt disponibile în Google Vids pentru: abonații Google AI Pro și Ultra ; clienții Google Workspace pentru business. Accesul la avatare personale este, deocamdată, limitat la anumite regiuni și doar pentru utilizatori de 18 ani sau mai mult . Avatarele sunt legate de contul Google al utilizatorului și sunt restricționate la „asemănarea” titularului contului, conform descrierii din material. Transparentizarea conținutului generat cu AI Google spune că fiecare clip generat include un watermark digital invizibil SynthID , menit să permită verificarea faptului că un video a fost creat cu inteligență artificială. Miza practică pentru companii este reducerea riscului de confuzie privind originea conținutului, într-un context în care materialele video generate devin mai ușor de produs și distribuit. Context: accelerarea producției video în Vids Google afirmă că, în ultimul an, utilizatorii au creat „milioane” de videoclipuri în Google Vids și amintește că, în februarie, a extins către toți utilizatorii integrarea Veo 3.1 pentru generare video în Vids. Noile funcții împing mai departe aceeași direcție: producție și editare video ghidate prin instrucțiuni text, cu personalizare la nivel de „prezentator” digital. [...]
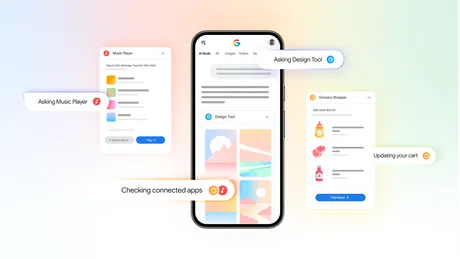
Google extinde „aplicațiile conectate” în AI Mode din Căutare, permițând utilizatorilor să lege servicii externe și să execute acțiuni direct din rezultate . Potrivit Google Blog , funcția începe să fie disponibilă „în această săptămână” în SUA, iar integrarea este gândită ca utilizatorii să poată interacționa „în siguranță” cu serviciile preferate fără să iasă din fluxul de căutare. Ce se schimbă operațional în Căutare Noutatea este că legarea aplicațiilor nu mai este limitată la aplicația Gemini, ci ajunge direct în Search, în AI Mode (modul de căutare asistat de inteligență artificială). Odată conectate, aceste servicii pot fi folosite pentru a duce la capăt sarcini concrete din răspunsurile generate. Google descrie câteva scenarii de utilizare: Instacart : utilizatorul poate adăuga ingredientele dintr-o listă de cumpărături direct în coșul Instacart și poate finaliza comanda cu câteva atingeri în aplicație sau pe site. Canva : utilizatorul poate cere sugestii de șabloane (de exemplu, pentru un fluturaș) direct din AI Mode. YouTube Music : utilizatorul poate crea o listă de redare și o poate salva instant în YouTube Music pentru redare. Cine poate folosi și când Google spune că funcția începe să fie implementată în această săptămână în SUA . Publicația nu oferă un calendar pentru extinderea în alte țări și nici o listă completă de parteneri disponibili la lansare, menționând doar că lucrează cu „o gamă” de parteneri și că vor urma și alte aplicații. Unde găsești opțiunea și ce înseamnă „aplicații conectate” Utilizatorii sunt direcționați către AI Mode din Search pentru a încerca „ connected apps ” (aplicații conectate). Google pune la dispoziție și o pagină de suport pentru funcție: connected apps , respectiv pagina AI Mode: AI Mode . În același context, compania reamintește că utilizarea datelor se face conform politicii sale de confidențialitate: Google’s privacy policy . [...]

România riscă o polarizare a economiei pe fondul adopției „informale” a inteligenței artificiale , în condițiile în care utilizarea reală în companii pare mult peste statisticile oficiale, dar fără competențe digitale suficiente și fără sprijin sistematic pentru tranziție, potrivit unei analize citate de Economedia . Analiza „AI – impact pe piața muncii: index de poziționare la nivel european”, realizată de IMM România , plasează România în categoria „decalaj semnificativ” față de media UE-27 în pregătirea pieței muncii pentru inteligența artificială. Țara are un index final de 52,5 din 100 (unde 100 reprezintă media UE-27), sub toate statele din grupul regional de comparație: Cehia (92,1), Ungaria (77,1), Polonia (74,8) și Bulgaria (59,9), și mult sub Estonia (106,1), indicată ca reper de bune practici. Adopția crește, dar decalajul față de UE rămâne Între 2021 și 2025, adopția IA în firmele românești cu peste 10 angajați a crescut de peste trei ori, de la 1,4% la 5,2%. În același interval, media europeană a urcat de la 7,7% la aproape 20%, menținând un raport de aproximativ unu la patru. Concluzia analizei este că, fără intervenții țintite, România riscă să rămână permanent în urmă. În plus, IMM România susține că adopția reală depășește semnificativ datele oficiale: într-un sondaj propriu, 66,1% dintre firmele respondente declară că folosesc deja cel puțin un instrument de tip IA, față de 5,2% cât indică statistica oficială pentru companiile cu peste 10 angajați. Vulnerabilitatea majoră: competențe digitale și inovare slabă Analiza indică drept punct cel mai vulnerabil pilonul de inovare și adaptare instituțională, cu un scor de 20,5, asociat cu cel mai redus nivel al cheltuielilor de cercetare-dezvoltare din Uniunea Europeană. Pe zona de capital uman, doar 31,8% dintre români au competențe digitale cel puțin de bază, față de 60,4% media UE, ceea ce plasează România la cel mai redus nivel din Uniune. În acest context, IMM România avertizează asupra unei distribuții inegale a capacității de adaptare: un nucleu de firme și angajați avansează rapid, în timp ce microîntreprinderile și lucrătorii din sectoare tradiționale (comerț, transport, HoReCa, industrie) rămân expuși, fără mijloace de tranziție. Ce măsuri cere IMM România și legătura cu AI Act (2026–2027) Florin Jianu, președintele IMM România, spune că viteza de adopție „pe cont propriu” poate accentua polarizarea dacă nu este susținută prin politici publice și programe de formare. „Datele ne arată un paradox: antreprenorii români adoptă inteligența artificială mult mai repede decât o vede statistica oficială, dar o fac pe cont propriu, fără sprijin, fără ghiduri și fără competențele de bază extinse în forța de muncă. Miza următorilor doi ani nu este dacă IA va transforma piața muncii din România, pentru că o face deja, ci dacă vom lăsa această transformare să polarizeze economia sau o vom transforma într-o oportunitate pentru toate firmele, inclusiv pentru IMM-uri.” IMM România solicită, între altele: operaționalizarea unui Program național de alfabetizare IA pentru forța de muncă, sub forma unor vouchere de formare pentru IMM-uri și angajați; programe active de reconversie prin partenerii sociali, orientate către sectoare cu expunere ridicată și capacitate redusă de absorbție; pregătirea din timp pentru termenele de aplicare 2026–2027 ale AI Act (regulamentul UE privind inteligența artificială). Analiza este construită pe nouă indicatori oficiali Eurostat , grupați în patru piloni (capital uman digital, digitalizarea firmelor, structura ocupării și inovare) și este completată de un sondaj realizat în rândul a 463 de IMM-uri. [...]


