Știri

Știri din categoria Inteligență artificială

OpenAI își întărește echipa de hardware prin recrutarea unui executiv-cheie de la Apple, într-un moment în care compania își concentrează eforturile pe un smartphone cu inteligență artificială care ar urma să concureze direct cu iPhone-ul, potrivit Wccftech.
Paul Meade, vicepreședinte de inginerie hardware în cadrul Vision Products Group de la Apple și responsabil de Vision Pro, dar și de inițiativa de ochelari inteligenți a companiei, pleacă la OpenAI, conform unei informații publicate de Bloomberg, citată de publicație. Meade ar urma să încheie săptămâna viitoare o carieră de 15 ani la Apple și să se alăture unității de hardware a OpenAI, care lucrează la dispozitive de consum bazate pe AI.
Materialul indică o schimbare de accent în planurile OpenAI pentru hardware de consum. Deși au fost vehiculate proiecte precum căști audio cu AI (cu nume de cod „Sweetpea”, posibil sub brandul „Dime”) și un dispozitiv de tip „pix” (nume de cod „Gumdrop”), analistul Ming-Chi Kuo a spus încă din aprilie că OpenAI ar fi „înghețat” temporar gama mai largă de dispozitive, concentrându-se în schimb pe un smartphone cu AI.
În această logică, aducerea unui lider cu experiență în inginerie hardware dintr-o divizie de produs majoră a Apple poate fi citită ca o întărire operațională a ambiției OpenAI de a livra un produs de volum, nu doar prototipuri sau dispozitive complementare.
Potrivit lui Kuo, citat de Wccftech, Luxshare ar urma să fie asamblorul principal pentru smartphone-ul OpenAI. Tot el susține că OpenAI s-ar fi orientat către o versiune personalizată a viitorului cip MediaTek Dimensity 9600 (SoC – „system-on-chip”, adică procesorul principal care integrează mai multe componente esențiale ale telefonului).
Publicația notează și câteva detalii tehnice asociate Dimensity 9600: ar urma să folosească procesul de fabricație TSMC N2P, iar varianta „Pro” este descrisă cu o configurație de nuclee CPU de tip 2+3+3, similară cu cea a unui viitor cip Qualcomm menționat în articol. Aceste informații rămân, însă, la nivel de raportări și așteptări din industrie, nu confirmări oficiale.
Wccftech plasează plecarea lui Meade și în contextul performanței slabe a Vision Pro în piața de masă și al calendarului extins pentru ochelarii inteligenți ai Apple: lansare „târziu în 2027”, cu ochelari AR (realitate augmentată) împinși către 2028 sau chiar 2029.
În paralel, publicația amintește o serie de plecări recente din Apple către competitori: un executiv important din zona Siri (Stuart Bowers) către Google DeepMind și alte schimbări la nivel de conducere, inclusiv în zona de AI și design de interfață. În plus, este menționat și faptul că Apple ar fi crescut bonusurile anuale pentru membri ai echipei de design iPhone, la un interval de 200.000–400.000 de dolari (aprox. 920.000–1.840.000 lei), în funcție de evoluția acțiunilor companiei, ca măsură de retenție.
În lipsa unor anunțuri oficiale despre un „telefon OpenAI”, informațiile rămân, deocamdată, în zona de recrutări și semnale din lanțul de aprovizionare—dar ele sugerează că următoarea bătălie pentru hardware de consum ar putea să se mute dinspre „gadgeturi AI” experimentale către smartphone-ul clasic, cu AI în centru.
Recomandate

OpenAI a lansat în regim de „preview” o nouă suită GPT-5.6 cu prețuri pe token semnificativ mai mici decât ale rivalilor , într-un moment în care compania se află sub presiune politică la Washington privind calendarul și siguranța lansărilor, potrivit The Verge . GPT-5.6 vine în trei variante: Sol (modelul „fanion”), Terra (nivel mediu, pentru „muncă de volum mare”) și Luna (model „rapid și accesibil” pentru utilizare de zi cu zi). OpenAI susține că noua generație este „în mod special” bună la programare, securitate cibernetică și biologie și că își menține mai bine concentrarea în sarcini de tip „agentic” pe orizont lung (adică fluxuri în care modelul execută pași multipli, relativ autonom, pentru a duce la capăt un obiectiv). Prețuri: Sol la 5 dolari input și 30 dolari output per milion de tokeni Publicația notează că GPT-5.6 Sol este tarifat la 5 dolari (aprox. 23 lei) pentru input și 30 dolari (aprox. 138 lei) pentru output per milion de tokeni. În comparație, este menționat Anthropic Claude Fable 5 , cu 10 dolari input și 50 dolari output per milion de tokeni. În aceeași schemă de preț: Terra costă „jumătate” din Sol; Luna costă „mai puțin de jumătate” din Terra. (Articolul nu oferă valorile exacte pentru Terra și Luna, doar relațiile de preț.) Două moduri noi pentru Sol: „max” și „ultra” OpenAI a introdus și două moduri suplimentare pentru Sol: „max” , descris ca fiind pentru „raționament mai profund”; „ultra” , pentru folosirea unor „sub-agenți” (componente care pot împărți sarcina în sub-sarcini). The Verge remarcă faptul că această abordare „evocă OpenClaw” și sugerează că ar putea indica direcția muncii lui Peter Steinberger la OpenAI, însă nu oferă detalii suplimentare verificabile despre implementare. Siguranță și utilizare abuzivă, în prim-plan pe fondul tensiunilor de reglementare În contextul unei „panici” de securitate la Washington, OpenAI și-a concentrat o mare parte din comunicare pe siguranță și riscuri de utilizare abuzivă. Compania afirmă că GPT-5.6 este antrenat să refuze asistența cibernetică interzisă, inclusiv atunci când utilizatorii încearcă să își mascheze intenția sau să „jailbreak”-uiască modelul (adică să ocolească restricțiile). OpenAI mai susține că Sol este mai bun la a ajuta oamenii să găsească și să repare vulnerabilități decât la a executa „cap-coadă” atacuri și că nu depășește pragul „cyber-critical” în cadrul propriului „preparedness framework” (cadru intern de evaluare a riscurilor). Articolul menționează însă că textul original continuă dincolo de fragmentul disponibil, astfel că nu pot fi redate eventuale nuanțe sau condiționări suplimentare. [...]

Administrația Trump cere OpenAI să lanseze etapizat următorul model , într-o mișcare care ar putea institui, în practică, un filtru guvernamental asupra accesului timpuriu la modele de vârf, cu efecte directe asupra vitezei de comercializare și a competiției din piața AI, potrivit The Next Web . Sam Altman le-a spus angajaților, miercuri, că Washingtonul vrea ca următorul model să fie oferit inițial doar unui „scurt” grup de parteneri de încredere, înainte de o distribuție mai largă. În această perioadă de previzualizare, guvernul ar urma să „aprobe accesul client cu client”, conform relatării. Cine cere și de ce contează Solicitarea nu ar veni dintr-un singur birou, ci din discuții cu două structuri: Office of the National Cyber Director și Office of Science and Technology Policy . Îngrijorarea este formulată ca una de securitate cibernetică, nu de concurență sau conținut: un model suficient de capabil ar putea fi folosit abuziv, iar lansarea în trepte ar limita expunerea în fereastra inițială. Miza, dincolo de cazul OpenAI, este mecanismul: dacă „aprobarea client cu client” funcționează așa cum este descrisă, o agenție guvernamentală ar avea un rol direct în a decide cine primește acces timpuriu la un model „frontieră” (de vârf, la limita capabilităților curente). Context: o schimbare de postură a Washingtonului Episodul se înscrie într-o schimbare mai amplă de abordare, notează publicația: vine la circa două săptămâni după ce Anthropic ar fi avut cele mai capabile oferte „retrase de pe piață” în urma unei directive guvernamentale, ceea ce sugerează că autoritățile încep să influențeze proactiv calendarele de lansare ale laboratoarelor, nu doar să reacționeze după apariția produselor. În același timp, situația amintește de lansarea controlată folosită de OpenAI pentru GPT-5.4-Cyber, oferit echipelor de securitate verificate printr-un program de „Trusted Access” (acces de încredere). Impact pentru OpenAI: încetinire comercială, dar și „acoperire” politică Pentru OpenAI, o lansare etapizată poate însemna o frână în a-și pune cel mai nou model în fața clienților plătitori și a dezvoltatorilor, într-o piață în care rivalii se mișcă rapid. Contextul e cu atât mai sensibil cu cât compania a lansat recent GPT-5.5 către segmentul enterprise (companii). Pe de altă parte, implicarea explicită a guvernului poate oferi și protecție politică: dacă apar probleme, responsabilitatea nu mai cade exclusiv pe companie. Ce rămâne neclar O parte importantă a detaliilor se bazează pe relatarea lui Altman către angajați și pe informații din surse, nu pe o declarație oficială a guvernului, iar OpenAI nu a publicat termenii aranjamentului. Inclusiv numele modelului, mecanismul de aprobare „client cu client” și agențiile implicate sunt prezentate ca provenind din aceste relatări. Întrebarea-cheie, în lectura The Next Web, este dacă acest tip de „poartă” guvernamentală devine un șablon pentru lansările viitoare ale modelelor de vârf din SUA. [...]
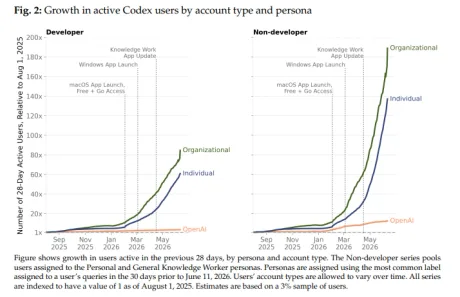
OpenAI susține că utilizarea Codex de către utilizatorii individuali a crescut de 137 de ori din august 2025 , un semnal că instrumentele de tip „agent” (care pot executa sarcini în mai mulți pași, pe durate mai lungi) ies din zona strict a programatorilor și intră tot mai mult în uzul general, potrivit IT Home . Datele apar într-un raport publicat de OpenAI pe 25 iunie, care urmărește evoluția utilizării Codex începând cu august 2025. Pe lângă creșterea de 137x la utilizatorii individuali non-dezvoltatori, OpenAI indică și o creștere de 189x pentru utilizarea în organizații (tot în rândul non-dezvoltatorilor), respectiv de 12x pentru utilizarea internă în companie. Ce arată cifrele despre adopție: dincolo de programatori În lucrarea „The Shift to Agentic AI: Evidence from Codex”, OpenAI afirmă că în prima jumătate din 2026 numărul utilizatorilor activi care folosesc „ agentic AI ” (IA de tip agent) a crescut de peste cinci ori, iar cea mai rapidă creștere a venit din afara segmentului de dezvoltare software. În interiorul OpenAI, compania spune că 97,9% dintre angajați folosesc Codex , față de aproximativ 40% în august 2025. În mediul extern, rata de utilizare în organizații ar fi urcat la 17,3% . Impact operațional: mai multe sarcini „lungi”, nu doar solicitări punctuale OpenAI mai susține că Codex, ca instrument de tip agent, poate rula sarcini pe perioade mai lungi. Un indicator folosit în raport: ponderea utilizatorilor Codex care au trimis cel puțin o solicitare de sarcină despre care se estimează că unui om cu experiență i-ar lua peste 8 ore să o finalizeze ar fi crescut de aproape zece ori de la începutul lui 2026. Documentul citat de OpenAI este disponibil aici: „THE SHIFT TO AGENTIC AI: EVIDENCE FROM CODEX” (PDF, OpenAI): https://cdn.openai.com/pdf/5d1e1489-21c0-43e4-9d42-f87efdbf0082/the-shift-to-agentic-ai-evidence-from-codex.pdf . [...]

OpenAI își mută o parte din „costul AI” în hardware propriu , printr-un cip de inferență (rulare a modelelor, nu antrenare) dezvoltat cu Broadcom , cu promisiunea unei eficiențe energetice semnificativ mai bune decât acceleratoarele de top de azi, potrivit OpenAI . Miza este una operațională și economică: inferența este zona care „atinge” utilizatorii (ChatGPT, Codex, API), iar orice câștig la consum și latență se poate traduce în costuri mai mici și capacitate mai mare în centrele de date. Cipul se numește Jalapeño și este descris ca primul „Intelligence Processor” al OpenAI, un accelerator proiectat de la zero pentru inferența LLM (modele lingvistice mari). Compania spune că Jalapeño este prima piesă dintr-o platformă de calcul pe mai multe generații, construită împreună cu Broadcom, pentru a face AI „mai rapid, mai fiabil și mai accesibil”. Ce promite Jalapeño și ce lipsește încă din date OpenAI afirmă că testele timpurii indică o „performanță pe watt” substanțial mai bună decât „state-of-the-art” (vârful actual al pieței), însă precizează că măsurătorile finale nu sunt încheiate. Un raport tehnic detaliat ar urma să fie prezentat „în lunile următoare”, ceea ce înseamnă că, deocamdată, nu există cifre publice comparabile (de tip throughput, latență, consum) care să cuantifice avantajul. În laborator, mostrele de inginerie rulează sarcini de machine learning la frecvența și puterea-țintă de producție, inclusiv „GPT‑5.3‑Codex‑Spark”, conform sursei. De ce contează pentru costuri și capacitate în centrele de date Unghiul principal al anunțului este eficiența în exploatare: OpenAI leagă direct îmbunătățirile de infrastructură de preț, viteză și disponibilitate pentru produse. Compania susține că arhitectura reduce mișcarea de date și echilibrează resursele de calcul, memorie și rețea pentru a obține o utilizare „mai aproape de vârful teoretic”. În termeni practici, OpenAI indică efecte posibile precum: răspunsuri mai rapide în ChatGPT; sarcini Codex care pot rula mai multe etape cu timpi de așteptare mai mici; costuri mai mici pentru produse bazate pe API; acces mai stabil în perioade de vârf. Cine face ce în proiect și când ar urma să fie implementat OpenAI spune că a proiectat cipul „de la zero” pe baza înțelegerii propriilor modele și sisteme de servire, iar Broadcom și Celestica au contribuit la industrializare: implementare silicon, plăci, integrare în rack-uri, rețelistică de înaltă performanță și sisteme de producție scalabile. Sunt menționate și tehnologii de rețea Broadcom, inclusiv „Tomahawk networking silicon”. Pe calendar, Jalapeño este descris ca primul pas al unei platforme multi-generație, cu „implementare inițială până la finalul lui 2026”. Broadcom afirmă că această colaborare ar permite implementarea unor centre de date „la scară de gigawați” cu Microsoft și alți parteneri, începând din 2026. Dezvoltare accelerată și rolul AI în proiectare Un alt element operațional este viteza: OpenAI afirmă că Jalapeño a ajuns de la design inițial la „manufacturing tape-out” (momentul în care designul este finalizat și trimis spre fabricație) în nouă luni și susține că acesta ar fi cel mai rapid ciclu de dezvoltare ASIC din semiconductori avansați de înaltă performanță. Compania adaugă că a folosit propriile modele pentru a accelera părți din procesul de proiectare și optimizare. Context suplimentar apare și în analiza Ars Technica , care reia ideea că Jalapeño este un ASIC specializat pentru inferență în centre de date și că OpenAI încă nu a publicat măsurători finale, urmând să vină cu un raport tehnic ulterior. În lipsa unor benchmark-uri publice, impactul real va depinde de datele tehnice promise și de ritmul în care OpenAI și partenerii pot duce cipul din laborator în producție și apoi în exploatare la scară mare, până la finalul lui 2026. [...]
Agenții AI mută munca de birou de la „întrebări punctuale” la sarcini delegate pe ore , iar datele interne prezentate de OpenAI arată că instrumentul său Codex a devenit, în mai puțin de un an, principalul mod de lucru cu AI în toate departamentele companiei, inclusiv în zone non-tehnice precum Juridic și Recrutare. Miza operațională este că AI nu mai este folosită doar ca „asistent de conversație”, ci ca executant de sarcini mai lungi, care rulează independent și coordonează instrumente. OpenAI descrie „agentic AI” (AI agentică) ca o schimbare de unitate a muncii de cunoaștere: de la interacțiuni scurte, autosuficiente, la sarcini delegate pe termen mai lung, în care agenții pot lucra minute sau ore, apelând instrumente și iterând până la soluție. În acest cadru, Codex este prezentat ca exemplu de produs care a accelerat trecerea de la chatbot la agent. Ce arată datele: sarcini mai lungi și utilizare dominantă în companie Potrivit analizei, utilizatorii folosesc Codex tot mai mult pentru activități estimate ca durată umană semnificativă. Până în mai 2026, în eșantionul de utilizatori individuali: 80,6% au făcut cel puțin o solicitare estimată la peste 30 de minute de muncă umană; 70,2% au făcut cel puțin o solicitare estimată la peste o oră; 25,6% au făcut cel puțin o solicitare estimată la peste opt ore. OpenAI mai notează că „aproape un sfert” din toate solicitările Codex vizează sarcini care ar lua unei persoane mai mult de o oră. În paralel, Codex a devenit instrumentul principal de lucru cu AI în interiorul companiei. Dacă până în august 2025 angajatul mediu OpenAI folosea Codex pentru mai puțin de 10% din „tokeni” (unități de text procesate/generate), acum utilizarea Codex depășește 85% din tokenii de ieșire ai angajatului mediu. La nivel agregat intern, OpenAI afirmă că Codex ajunge la 99,8% din tokenii săptămânali de ieșire generați în companie, menționând și că utilizatorii Codex tind să consume mai mulți tokeni decât non-utilizatorii. Extinderea dincolo de ingineri: Juridic, Financiar, Recrutare Tranziția a început în inginerie, unde, potrivit OpenAI, utilizarea s-a mutat majoritar către Codex până în decembrie 2025, iar „astăzi” inginerul mediu generează 99% din tokenii de ieșire cu Codex, nu cu ChatGPT. Departamentele non-tehnice (Juridic, Financiar, Recrutare) ar fi trecut la Codex ca instrument principal în jurul lunii aprilie 2026, însă „mult mai rapid”, iar un avocat sau recrutor mediu ar genera acum peste 85% din tokenii de ieșire în Codex. În ultimele șase luni (raportat la perioada analizată), OpenAI indică o intensificare a utilizării interne, măsurată prin creșterea tokenilor de ieșire combinați pe departamente. Exemplele oferite: Research: utilizare mediană de 56 de ori mai mare în iunie 2026 față de noiembrie 2025; Customer Support: +32 ori; Engineering: +27 ori; Legal: +13 ori. De ce contează pentru companii: cost mai mic de a trece granițele dintre roluri Un punct central al materialului este că adoptarea accelerată în rândul non-dezvoltatorilor poate schimba modul în care sunt proiectate fluxurile de lucru. OpenAI susține că agenții reduc costul de a trece între tipuri de sarcini și permit angajaților să execute „muncă adiacentă” care înainte necesita sprijin tehnic specializat. Ca exemplu intern, OpenAI afirmă că, în funcțiile de business, „peste un sfert” din munca realizată cu Codex ar fi fost inginerie sau programare, ceea ce sugerează o creștere a autonomiei operaționale în departamente care, tradițional, depind de echipe tehnice pentru automatizări, transformări de date, instrumente, depanare sau analiză structurată. Ce urmează, în logica OpenAI Concluzia OpenAI este că, pe măsură ce instrumentele agentice devin mai capabile și mai accesibile, utilizatorii le vor folosi pentru sarcini mai lungi, mai complexe și mai „transversale” între funcții. Companiile sunt puse, implicit, în fața unei decizii de organizare: dacă tratează AI ca un canal de suport (chat) sau ca o resursă de execuție delegată (agenți) care poate prelua bucăți consistente din munca de cunoaștere. [...]

OpenAI își atacă costurile de rulare ale modelelor printr-un cip propriu pentru „inference” (executarea modelelor deja antrenate), dezvoltat împreună cu Broadcom, într-o mișcare care poate reduce dependența companiei de plăcile grafice Nvidia și poate îmbunătăți economia serviciilor sale, potrivit TechCrunch . Procesorul, numit Jalapeño , este descris ca primul cip personalizat al OpenAI pentru inferență, proiectat și fabricat în colaborare cu Broadcom. Compania spune că propriile sale modele de inteligență artificială au ajutat la dezvoltarea cipului. Deși Jalapeño este încă în testare, OpenAI afirmă că rezultatele timpurii indică o performanță „semnificativ mai bună per watt” față de alternativele de vârf existente. În practică, o eficiență energetică mai bună poate însemna costuri mai mici pentru a rula modele în timp real, acolo unde cererea este continuă și volumul de solicitări este mare. De ce contează: inferența e o linie majoră de cost OpenAI poziționează Jalapeño ca un cip optimizat pentru inferență, adică pentru răspunsul la comenzi ale utilizatorilor folosind modele deja construite. În anunț, compania a pus accent pe costul redus de operare atunci când rulează modele de programare în timp real. TechCrunch notează că sarcinile mai intensive, precum pre-antrenarea (pre-training), ar urma probabil să rămână pe hardware Nvidia, însă chiar și reduceri mici ale costurilor de inferență pot avea un efect vizibil asupra profitabilității. Context: aceeași direcție ca Google și Amazon Parteneriatul OpenAI–Broadcom fusese anunțat oficial în octombrie, iar planurile OpenAI privind cipuri proprii au fost discutate de mai mult timp ca soluție pentru a reduce dependența de GPU-urile Nvidia. În același timp, Google și Amazon au mers pe o strategie similară, dezvoltând cipuri dedicate pentru accelerarea sarcinilor de învățare automată („acceleratoare AI”) — de exemplu, TPU la Google și Trainium la Amazon. Ce urmează: optimizare „pe tot stack-ul”, dar cipul e încă în testare Președintele OpenAI, Greg Brockman , a explicat într-un episod al podcastului intern al companiei că abordarea pornește de la înțelegerea detaliată a sarcinilor de lucru și de la identificarea zonelor „insuficient deservite”, unde un cip dedicat poate accelera semnificativ execuția. În mesajul companiei, OpenAI își descrie strategia ca o optimizare la nivelul întregii infrastructuri — de la arhitectura cipului și componente software de bază (precum „kernels”, adică rutine optimizate care rulează pe hardware) până la rețelistică, planificarea rulărilor și sistemele de implementare. Totuși, Jalapeño nu este încă un produs confirmat ca fiind în producție la scară largă: deocamdată, OpenAI spune doar că îl testează și că are rezultate preliminare promițătoare. [...]




