Știri

Știri din categoria Inteligență artificială

NVIDIA își extinde ecosistemul de „AI Cloud” pentru a crește rapid capacitatea de calcul necesară aplicațiilor cu agenți AI, pe fondul unei cereri în creștere pentru „tokeni” (unități de procesare a textului/ieșirilor modelelor) și pentru infrastructură regională, inclusiv în contexte suverane și reglementate, potrivit NVIDIA.
Unghiul principal al mișcării este operațional: furnizorii de cloud și partenerii NVIDIA accelerează construcția de „AI factories” (centre de date optimizate pentru antrenare și inferență AI) mai aproape de date, dezvoltatori și utilizatori, pentru a reduce fricțiunea de acces la infrastructură și pentru a susține aplicații „agentice” (sisteme AI care execută sarcini în lanț, cu autonomie mai mare).
Publicația descrie NVIDIA AI Clouds ca un ecosistem de cloud-uri „proiectate special” și co-dezvoltate cu infrastructura completă NVIDIA (calcul accelerat, rețelistică și software AI), care acoperă antrenare, ajustare fină (fine-tuning), inferență, aplicații agentice, „physical AI” (AI pentru robotică și sisteme fizice) și implementări de tip „sovereign AI” (control local asupra datelor și infrastructurii).
În acest context, extinderea are o componentă de conformitate și control: pentru guverne și industrii reglementate, cloud-urile regionale pot susține cerințe de conformitate locală și „controale suverane”, iar pentru companii și dezvoltatori pot facilita rularea serviciilor AI „aproape de utilizatori și date” (de exemplu, copiloți enterprise, „digital workers” și alți agenți AI).
NVIDIA afirmă că ecosistemul ajunge acum pe șase continente, după adăugarea Cassava în Africa și Claro în America de Sud. Creșterea regională este indicată ca accelerând în Asia de Sud-Est, Australia și Americi.
În paralel, sunt menționați parteneri care își extind infrastructura pentru dezvoltarea de modele de vârf, aplicații agentice și inferență la volum mare, între care CoreWeave, Firmus, IREN, Nebius și Nscale.
Textul oferă câteva exemple de implementare:
Separat, NVIDIA notează că șase parteneri au obținut statutul de Exemplar Cloud: CoreWeave, Crusoe, Lambda, Nebius, Vultr și YTL.
NVIDIA pune accent pe economie și eficiență operațională, argumentând că, pe măsură ce AI se mută de la dezvoltarea modelelor la „reasoning” și inferență la volum mare, criteriul nu mai este doar capacitatea instalată, ci și „economia” producției de tokeni.
Compania descrie „cost per token” ca indicator de cost total de deținere (TCO), care include performanța hardware, optimizările software, suportul de ecosistem și utilizarea în condiții reale, și susține că livrează „cel mai mic cost per token” din industrie (fără a oferi cifre în materialul citat). Pentru accelerarea implementărilor, NVIDIA arată că partenerii adoptă platforma NVIDIA DSX (detalii: NVIDIA DSX platform), care include componente pentru simulare înainte de implementare, adaptarea sarcinilor la condițiile rețelei electrice și automatizarea operațiunilor.
Potrivit descrierii din text, una dintre componentele DSX (DSX MaxLPS) ar permite, în condiții de limitare de putere, „până la 40% mai multe GPU-uri” în același buget energetic, prin maximizarea calculului în limitele de consum.
Din informațiile prezentate, direcția imediată este creșterea capacității regionale și standardizarea operării „AI factories” prin platforme precum DSX, în paralel cu extinderea cazurilor de utilizare către aplicații agentice și „physical AI”. Materialul nu include un calendar de livrare sau ținte cantitative agregate pentru capacități, astfel că ritmul exact al extinderii rămâne neprecizat.
Recomandate

Marina SUA va folosi un supercomputer Nvidia DGX GB300 pentru a pregăti ofițeri să evalueze limitele și riscurile IA , după ce compania a donat sistemul către Naval Postgraduate School din Monterey, potrivit The Next Web . Miza operațională nu este doar creșterea capacității de calcul, ci formarea unor decidenți care să nu „aibă încredere oarbă” în modele și să știe când tehnologia nu trebuie folosită. Sistemul, descris ca primul supercomputer IA de acest tip din armata americană, rulează pe generația Blackwell Ultra — aceeași linie de cipuri pe care SUA interzice să o vândă către firme chineze. În acest caz, Nvidia a oferit echipamentul gratuit, printr-o donație către fundația școlii, notează publicația, citând o relatare Nextgov . Ce include sistemul și cum va fi folosit DGX GB300 este prezentat ca un sistem integrat (nu un centru de date), care se poate conecta la infrastructura existentă de energie și apă a campusului. Configurația menționată în articol include: 36 procesoare Grace (CPU); 72 plăci grafice Blackwell Ultra (GPU), conectate pentru procesare paralelă. Școala spune că îl va utiliza pentru instruire și aplicații în domenii precum modelare meteo și oceanografică, cercetare operațională, securitate cibernetică și planificare de reziliență. La punerea în funcțiune au contribuit și companii precum Vertiv, DDN și VAST Data. De ce contează: accent pe „judecată”, nu pe „putere de foc” În articol, Naval Postgraduate School își definește explicit obiectivul ca fiind educarea viitorilor lideri militari să înțeleagă suficient de bine aceste tehnologii încât să le poată evalua limitele și să le aplice „etic” și „responsabil”. Căpitanul Michael Owen, vice-provost al Marinei, este citat astfel: „Întrebarea nu este dacă aceste tehnologii vor exista, ci dacă viitorii lideri militari le înțeleg suficient de bine încât să le evalueze limitările, să le aplice etic și să le folosească responsabil.” Dincolo de utilizările academice, donația are și o componentă strategică: un cip considerat prea sensibil pentru export către China ajunge instrument de instruire pentru ofițeri americani, iar Nvidia își expune, în același timp, hardware-ul orientat către zona militară. Context: parteneriat început în 2024 Supercomputerul se bazează pe un acord de cercetare între Nvidia și școală, semnat în decembrie 2024. Potrivit articolului, colaborarea a dus deja la un AI Tech Center în 2025, echipat cu cipuri Blackwell, dispozitive Jetson și platforma de simulare Omniverse. În ansamblu, mesajul instituției este că valoarea principală a noii infrastructuri nu stă doar în capacitatea de calcul, ci în antrenarea discernământului: când și în ce condiții cele mai avansate sisteme de IA nu ar trebui considerate de încredere. [...]

Jensen Huang susține că panica privind dispariția masivă a locurilor de muncă din cauza AI este „o prostie totală” și avertizează că riscul real pentru angajați vine din competiția cu cei care folosesc deja aceste instrumente, potrivit The Next Web . Într-un interviu amplu acordat Axios, șeful Nvidia a respins două idei pe care le vede drept exagerări: că inteligența artificială „va pune capăt omenirii” și că va elimina jumătate dintre joburile din SUA. Huang spune că „toate dovezile” indică „exact opusul”, însă argumentul lui nu este că munca nu se schimbă, ci că oamenii confundă „o sarcină” cu „un job”. „Sarcina” se automatizează, „jobul” se redefinește Huang folosește exemplul radiologilor: citirea scanărilor este o sarcină pe care AI o poate face în mare parte, dar jobul ar rămâne legat de reducerea suferinței și ghidarea pacienților. În aceeași logică, el admite că munca din call-center este „foarte probabil” să fie puternic automatizată, însă consideră că judecata și decizia rămân umane. Pentru a-și susține poziția, Huang invocă și câteva cifre (prezentate ca afirmații ale sale în interviu): numărul radiologilor ar fi în creștere cu aproximativ 20%, deoarece AI le permite să vadă mai mulți pacienți; numărul paralegalilor ar fi în creștere cu circa 10%; joburile din manufactură ar fi crescut cu aproximativ 50% în ultimii ani, pe fondul cursei pentru construirea de centre de date. Mesajul său, formulat direct, mută discuția de la „AI îți ia jobul” la competiția între oameni: „AI nu o să ne distrugă toate joburile. Cineva care folosește AI o să-ți ia jobul.” Miza pentru companii: productivitate și presiune pe recalificare Din perspectiva impactului economic și operațional, poziția lui Huang sugerează că firmele care integrează rapid AI pot obține un avantaj de productivitate, iar cele care întârzie riscă să piardă competitivitate. În același timp, angajații sunt împinși spre adaptare: dacă automatizarea „taie” sarcini, valoarea se mută către activități care cer decizie, relaționare și responsabilitate profesională. Țintă către „doomeri” și un avertisment pentru Washington Huang a criticat și narativele apocaliptice promovate, în opinia lui, de lideri din industrie care „petrec prea mult timp teoretizând” scenarii de tip science-fiction, pentru că „îi face să pară inteligenți”. El spune că discuțiile despre singularitate, simulare sau conștiință a mașinilor sunt „inventate” și că, deși e legitim „să avertizezi oamenii”, este „absolut nepotrivit să inventezi lucruri”. În relația cu factorii de decizie, Huang avertizează că politicienii pot „supra-corecta” dacă „cad în plasa acestor narațiuni”. În același registru, el le-ar fi recomandat administrației Trump să discute cu mulți oameni de știință, nu cu „unul sau doi”, și a respins ideea ca guvernul să ia o participație în Nvidia, pe care o consideră „inutilă”. Context: optimismul lui Huang și interesul Nvidia Huang își proiectează o viziune puternic optimistă: se așteaptă la „un trilion” de agenți AI care rulează simultan și spune că „momentul ChatGPT” pentru roboți a sosit deja, cu mașini utile posibil la 3–4 ani distanță. Acceptă că o bulă AI „va veni într-o zi”, dar „nu azi” și probabil nu în următorii cinci ani. The Next Web notează însă și interesul evident al Nvidia: mai mult AI înseamnă cerere mai mare pentru cipurile companiei. În plus, rivali precum Dario Amodei (Anthropic) ar prognoza contrariul în privința efectelor asupra joburilor. În acest cadru, distincția lui Huang între „sarcină” și „job” rămâne, totuși, nucleul argumentului: automatizarea schimbă munca, dar nu o anulează — iar riscul imediat este competiția cu cei care folosesc AI mai bine și mai repede. [...]

Google semnează codul UE de transparență pentru conținut generat de IA , un pas care poate influența direct modul în care companiile vor trebui să eticheteze și să dovedească originea materialelor online în Europa, dar care vine și cu un avertisment privind riscul de „supra-reglementare”, potrivit Google . Aderarea vizează EU AI Act Code of Practice on Transparency of AI-Generated Content (cod de practică asociat Actului european privind inteligența artificială), disponibil la nivelul Comisiei Europene aici . Google spune că demersul se bazează pe semnarea, în 2025, a GPAI Code of Practice (un set de angajamente voluntare pentru IA), menționat într-un material separat al companiei aici . Ce înseamnă operațional: etichetare și „amprentare” digitală a conținutului În centrul abordării Google este accelerarea adoptării standardului industrial C2PA (un standard pentru proveniența conținutului digital) și dezvoltarea de instrumente de transparență, inclusiv SynthID . Compania descrie SynthID drept o tehnologie de „watermarking” (marcare digitală) care ajută utilizatorii să înțeleagă cum a fost creat și editat conținutul. Referințe: C2PA și SynthID . Google afirmă că lucrează și cu laboratoare terțe de IA pentru a susține adoptarea pe scară largă a unor instrumente interoperabile de marcare bazate pe SynthID, enumerând Apple, Eleven Labs, Kakao, NVIDIA și OpenAI. Miza de reglementare: transparență, dar fără „straturi” care se bat cap în cap Deși susține obiectivul de transparență, Google avertizează că adăugarea de complexitate de reglementare , într-un moment în care soluțiile tehnice „încă evoluează”, ar putea intra în contradicție cu obiectivele Europei legate de competitivitate și simplificare și ar putea crea confuzie pentru utilizatori. Compania susține că, dacă mediul online ajunge „inundat” de etichete suprapuse și divulgări legale, oamenilor le va fi mai greu să obțină contextul de care au nevoie pentru a înțelege ce văd. Ce urmează Pe măsură ce codul este implementat, Google spune că va lucra cu autoritățile de reglementare și cu parteneri pentru a construi soluții „practice” care să ofere transparență „reală” și să ajute utilizatorii să ia decizii informate despre conținutul pe care îl consumă online. [...]

România trebuie să aplice din 2 august 2026 Regulamentul UE privind inteligența artificială , iar asta înseamnă desemnarea autorităților de supraveghere, stabilirea atribuțiilor și a regimului de sancțiuni, potrivit Economica . Miza pentru companii este una de reglementare: de la această dată, cadrul european devine aplicabil, iar România trebuie să aibă mecanisme funcționale de control și penalizare a încălcărilor. În acest context, printr-un Memorandum al Guvernului, ANCOM a fost propusă pentru rolul de autoritate națională de supraveghere a pieței și punct național unic de contact, alături de alte autorități cu atribuții sectoriale. Cine supraveghează aplicarea și pe ce zone Memorandumul menționat în materialul ANCOM conturează o arhitectură de supraveghere pe domenii, în special pentru sistemele de inteligență artificială „cu grad ridicat de risc”: ANCOM – propusă ca autoritate națională de supraveghere a pieței și punct național unic de contact; Autoritatea de Supraveghere Financiară (ASF) și Banca Națională a României (BNR) – pentru sistemele de AI cu grad ridicat de risc din serviciile financiare ; Autoritatea Națională de Supraveghere a Prelucrării Datelor cu Caracter Personal – pentru AI cu grad ridicat de risc din biometrie , utilizată în scopul aplicării legii, gestionării frontierelor și în zona justiției și democrației. Potrivit informațiilor, autoritățile desemnate lucrează împreună cu alte instituții sectoriale la cadrul legislativ național necesar aplicării regulamentului. Ce trebuie să conțină cadrul național: atribuții, cooperare, sancțiuni Actul normativ național aflat în lucru ar urma să stabilească, între altele: autoritățile de supraveghere a pieței și atribuțiile lor; mecanismele de cooperare între autorități; procedura de sancționare și regimul sancțiunilor pentru încălcarea regulamentului. Calendar: ce intră în vigoare acum și ce se amână Conform calendarului indicat (art. 113), Regulamentul UE privind AI devine aplicabil din 2 august 2026 , cu excepții pentru anumite obligații legate de sistemele cu grad ridicat de risc, care se aplică ulterior: din 2 decembrie 2027 – pentru sistemele cu grad ridicat de risc enumerate în Anexa III ; din 2 august 2028 – pentru sistemele încadrate ca având grad ridicat de risc potrivit articolului 6 alineatul (1) și Anexei I . Separat, interdicțiile pentru sistemele de AI cu „risc inacceptabil” au intrat în vigoare la 2 februarie 2025 , însă Regulamentul „Omnibus” în domeniul digital introduce două noi categorii de practici interzise , aplicabile de la 2 decembrie 2026 : sisteme care pot genera sau modifica imagini/video/audio realiste cu părțile intime ori cu acte sexuale explicite ale unei persoane identificabile, fără consimțământ ; sisteme care pot genera sau modifica materiale ce constituie pornografie infantilă sau spectacole de pornografie infantilă. Obligații de transparență pentru conținut sintetic și deepfake Noile prevederi introduc obligații pentru furnizori și implementatori ai unor sisteme de AI, inclusiv pentru cele care: interacționează direct cu persoane fizice; generează conținut sintetic (audio, imagine, video, text); generează sau modifică conținut care constituie deepfake (conținut fals realist); generează sau modifică texte publicate pentru informarea publicului pe teme de interes public. ANCOM precizează și o excepție pentru sistemele deja introduse pe piață înainte de 2 august 2026, în ceea ce privește marcarea conținutului generat: „Excepţia o reprezintă sistemele de IA, inclusiv de sisteme de IA de uz general, care generează conţinut sintetic în format audio, imagine, video sau text, care au fost introduse pe piaţă înainte de 2 august 2026, în cazul cărora obligaţia furnizorilor de a marca conţinutul generat se aplică începând cu 2 decembrie 2026.” În același comunicat sunt definite și rolurile din lanț: „furnizorii” (cei care dezvoltă sau comandă dezvoltarea și introduc pe piață/pun în funcțiune sub propriul nume) și „implementatorii” (cei care utilizează sistemul, cu excepția utilizării personale, neprofesionale). Pentru mediul de afaceri, următorul pas practic este finalizarea cadrului legislativ național (inclusiv sancțiunile și procedurile), astfel încât aplicarea de la 2 august 2026 să nu rămână doar o obligație formală, ci una efectivă. [...]

România trebuie să-și definitiveze rapid arhitectura de supraveghere și sancțiuni pentru AI , deoarece Regulamentul european privind inteligența artificială devine aplicabil de la 2 august 2026, iar ANCOM este propusă să aibă un rol central de coordonare, potrivit Antena 3 , care citează un comunicat al autorității. Regulamentul obligă fiecare stat membru să desemneze una sau mai multe autorități competente care să supravegheze aplicarea și să stabilească norme naționale privind organizarea instituțională și regimul sancționator. În România, printr-un Memorandum al Guvernului, ANCOM a fost propusă drept autoritate națională de supraveghere a pieței și punct național unic de contact, alături de alte autorități sectoriale. Cine supraveghează ce: împărțirea pe domenii Conform informațiilor prezentate, Memorandumul indică și alte autorități cu rol de supraveghere, în funcție de sector și de tipul de sistem AI cu grad ridicat de risc: ASF și BNR – pentru sistemele de AI cu grad ridicat de risc din sectorul serviciilor financiare ; Autoritatea Națională de Supraveghere a Prelucrării Datelor cu Caracter Personal – pentru sistemele de AI cu grad ridicat de risc din biometrie , utilizate în scopul aplicării legii, gestionării frontierelor și în zona justiției și democrației. ANCOM precizează că autoritățile desemnate lucrează împreună cu alte instituții sectoriale la cadrul legislativ național necesar aplicării Regulamentului. Ce trebuie să conțină legea națională de implementare Actul normativ național aflat în lucru ar urma să stabilească, între altele: autoritățile de supraveghere a pieței și atribuțiile acestora; mecanismele de cooperare între autorități; procedura de sancționare și regimul sancțiunilor pentru încălcarea Regulamentului. Pentru companii și instituții publice care dezvoltă sau folosesc AI, miza este dublă: claritatea privind „cine controlează” în fiecare domeniu și predictibilitatea sancțiunilor, odată ce regulile devin aplicabile. Calendar: ce intră în vigoare și când ANCOM indică faptul că, potrivit calendarului din Regulament (art. 113), cu modificările aduse de „Regulamentul Omnibus” în domeniul digital privind AI (publicat vineri de Comisia Europeană), Regulamentul privind AI devine aplicabil de la 2 august 2026 , cu excepții. Pentru anumite obligații legate de sistemele AI cu grad ridicat de risc, aplicarea este decalată: 2 decembrie 2027 – pentru sistemele cu grad ridicat de risc enumerate în Anexa III ; 2 august 2028 – pentru sistemele clasificate ca prezentând grad ridicat de risc în temeiul articolului 6 alineatul (1) și al Anexei I . Separat, interdicțiile privind sistemele AI cu risc inacceptabil au intrat în vigoare la 2 februarie 2025 , însă „Regulamentul Omnibus” introduce încă două categorii de practici interzise, aplicabile de la 2 decembrie 2026 : sisteme care pot genera/modifica imagini sau materiale realiste cu părți intime ori acte sexuale explicite fără consimțământ și sisteme care pot genera/modifica materiale ce constituie pornografie infantilă sau spectacole de pornografie infantilă. Obligații pentru furnizori și implementatori, inclusiv pentru „deepfake” și conținut sintetic Noile prevederi includ obligații pentru furnizorii și implementatorii unor sisteme de AI, inclusiv cele care: interacționează direct cu persoane fizice; generează conținut sintetic (audio, imagine, video sau text); generează sau modifică conținut care constituie deepfake (conținut audio/video/imagine manipulat realist); generează sau modifică texte publicate pentru informarea publicului pe teme de interes public. ANCOM notează și o excepție: pentru sistemele (inclusiv AI de uz general) care generează conținut sintetic și au fost introduse pe piață înainte de 2 august 2026, obligația furnizorilor de a marca conținutul generat se aplică din 2 decembrie 2026 . În comunicat sunt definite și rolurile: „furnizorii” sunt cei care dezvoltă sau comandă dezvoltarea și introduc pe piață/pun în funcțiune sistemul sub propriul nume, iar „implementatorii” sunt cei care utilizează un sistem AI aflat sub autoritatea lor, cu excepția utilizării personale, fără caracter profesional. [...]
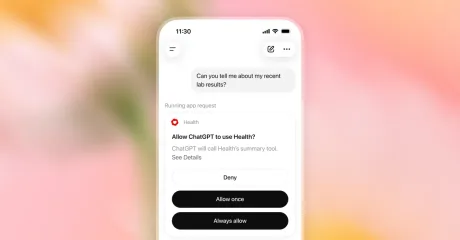
OpenAI extinde ChatGPT Health în SUA și ridică miza pe piața sănătății , susținând că modelele sale pot „raționa” la un nivel „mai bun decât cel al clinicianului”, potrivit The Verge . Lansarea către toți utilizatorii din SUA are loc joi și permite conectarea dosarelor medicale și a datelor de monitorizare a sănătății la chatbot, într-un moment în care compania este deja sub presiune din cauza riscurilor asociate recomandărilor medicale generate de AI. Într-un briefing, Ashley Alexander, vicepreședinte OpenAI pentru produse de sănătate, a afirmat că modelele companiei „sunt acum capabile să raționeze la niveluri care sunt mai bune decât nivelul clinicianului”. Totuși, liderul OpenAI pe zona de sănătate, Karan Singhal, a nuanțat ulterior această poziție, spunând că ar „temper[a]” afirmația privind depășirea clinicianilor, deși a invocat existența unor „studii individuale” care ar indica această direcție, inclusiv unul realizat de Harvard și Stanford, conform aceleiași surse. Ce se schimbă operațional pentru utilizatori Odată cu extinderea, utilizatorii pot pune întrebări despre informațiile medicale conectate direct în experiența principală de chat, fără să mai fie nevoiți să navigheze către un tab dedicat ChatGPT Health. OpenAI spune că ChatGPT va cere permisiunea înainte de a folosi datele de sănătate pentru personalizarea răspunsurilor și că „toate conversațiile sunt criptate în repaus și în tranzit”, iar informațiile conectate în Health beneficiază de „protecție suplimentară prin criptare”. Utilizatorii pot, de asemenea, să revizuiască și să modifice tipurile de date conectate, inclusiv: notițe de după vizite medicale; notițe de la echipa de îngrijire; rezultate de laborator; medicație. Context: lansare pe fondul disputelor privind siguranța recomandărilor medicale Extinderea vine la câteva săptămâni după ce OpenAI a lansat GPT-5.6 Sol , pe care compania îl descrie drept „cel mai puternic model de până acum pentru sănătate”; ChatGPT Health va rula pe cele mai recente modele ale companiei. În paralel, The Verge notează că miercuri un pastor din Florida a dat în judecată OpenAI, susținând că ChatGPT i-ar fi oferit „recomandări medicale extrem de periculoase”, care l-ar fi determinat să amâne îngrijirea medicală pentru o embolie pulmonară. [...]

