Știri

Știri din categoria Inteligență artificială

Nokia și Orange își aliniază dezvoltarea AI-RAN pentru performanță și eficiență energetică în rețele, într-un demers care mută accentul dinspre simple teste de laborator spre definirea unor capabilități ce pot fi integrate în exploatarea curentă a rețelelor. Potrivit Mobile World Live, cele două companii vor dezvolta împreună cazuri de utilizare pentru AI-RAN, cu sprijinul infrastructurii de inteligență artificială a Nvidia.
Colaborarea este organizată într-un cadru de „co-inovare”, în care Nokia și Orange vor identifica, proiecta și evalua capabilități noi pentru AI-RAN (aplicarea inteligenței artificiale în rețeaua de acces radio – RAN, componenta care conectează utilizatorii la rețeaua mobilă).
Inițiativa vizează, în principal, îmbunătățiri măsurabile în funcționarea rețelei, pe trei direcții menționate de companii:
Nokia și Orange au indicat și o componentă orientată spre evoluția către 6G: co-dezvoltarea unor abordări „pentru maximizarea eficienței spectrale” în benzile existente și viitoare, inclusiv în zona „upper 6GHz” (peste 6 GHz).
Companiile descriu platforma drept „pregătită pentru 6G”, cu o migrare lină, definită prin software (adică bazată pe actualizări și funcții software, nu doar pe schimbări de echipamente), și cu o utilizare mai „inteligentă” a resurselor de calcul la nivelul amprentei operatorului.
Orange a precizat că, lucrând cu Nokia și Nvidia, urmărește să-și aprofundeze înțelegerea modului în care funcțiile RAN bazate pe AI pot fi integrate în rețele, „asigurând” în același timp o utilizare sustenabilă și eficientă a resurselor în Europa, Orientul Mijlociu și Africa.
Pallavi Mahajan, director de tehnologie și AI, a afirmat că AI schimbă modul în care sunt proiectate rețelele și că parteneriatul este „instrumental” pentru tranziția industriei către rețele „cognitive”, „AI-native” (construite nativ pentru a folosi AI).
În context, publicația notează că, la MWC26 Barcelona, Nokia a prezentat parteneriatul AI-RAN cu Nvidia, indicând integrări la operatori și teste reușite ale funcțiilor AI-RAN accelerate cu GPU.
Recomandate

Comisia Europeană a deschis licitația pentru până la șapte „gigafabrici” de inteligență artificială, dar finanțarea publică este încă în mare parte neasigurată , ceea ce pune sub semnul întrebării calendarul și capacitatea UE de a recupera rapid decalajul față de SUA și China, potrivit The Next Web . Inițiativa este prezentată ca un efort de circa 30 miliarde euro, construit pe un parteneriat public-privat: aproximativ 10 miliarde euro ar urma să vină de la Bruxelles și statele membre, iar restul de 20 miliarde euro de la investitori privați, pe ideea că banii publici pot „atrage” capitalul necesar proiectelor. Ce se cumpără, concret: putere de calcul la scară mare Fiecare „gigafabrică” ar urma să găzduiască cel puțin 100.000 de cipuri avansate pentru AI, ceea ce ar face-o de circa patru ori mai puternică decât cele mai mari centre de date care operează în prezent în UE. Împreună, cele până la șapte unități ar urma să dubleze (și chiar să depășească) capacitatea de calcul pentru AI a blocului comunitar. Comisia diferențiază aceste proiecte de rețeaua existentă de 19 „fabrici AI” mai mici, atașate supercomputerelor europene: noile amplasamente sunt gândite „cu un ordin de mărime” mai mari, pentru antrenarea modelelor de vârf (frontier models) pe care, în prezent, doar câteva laboratoare din SUA și China și le permit. Miza economică: UE încearcă să reducă dependența de „compute” închiriat Rațiunea proiectului este una competitivă: companiile europene ajung să închirieze putere de calcul (compute) de la furnizori americani de cloud, în timp ce SUA și China investesc masiv în infrastructură. Henna Virkkunen, responsabilă în Comisie pentru „suveranitatea tehnologică”, numește această scară de calcul „o necesitate strategică”. Interesul de piață există: o rundă anterioară de exprimare a interesului a strâns 76 de răspunsuri din partea unor consorții din Europa, iar zece țări – inclusiv Germania, Franța, Italia, Spania și Polonia – s-au poziționat ca potențiale gazde. Franța a semnalat deja că ar putea merge pe cont propriu. Problema-cheie: banii publici sunt, deocamdată, mai mult „intenție” Deși proiectul este prezentat ca având o componentă publică de circa 10 miliarde euro, doar aproximativ 1 miliard euro din partea Bruxelles-ului este efectiv angajat, restul depinzând de următorul buget multianual al UE (Multiannual Financial Framework), care nu este încă agreat. Un oficial de rang înalt a spus explicit că suma este o „cea mai bună estimare” a ceea ce ar putea fi disponibil, nu bani deja alocați: „Nu putem anticipa deciziile privind următorul MFF.” Această incertitudine intră în conflict cu un calendar ambițios: construcția ar trebui să înceapă la începutul lui 2027, iar primele „gigafabrici” să devină operaționale la mijlocul lui 2028. Riscuri operaționale: întârzieri, energie scumpă și dependență de cipuri americane Planul a fost lansat inițial la începutul lui 2025 și „a alunecat” de mai multe ori, ceea ce sugerează prudență în privința termenelor. În plus, există două constrângeri structurale: Lanțul de aprovizionare cu cipuri : cipurile ar urma să vină în principal de la Nvidia, AMD și Qualcomm – companii americane – ceea ce complică mesajul de „independență”. Costul energiei : electricitatea în Europa este de două până la trei ori mai scumpă decât în SUA sau China, iar alimentarea centrelor de date este deja un factor limitativ. Criticii citați de publicație pun sub semnul întrebării modelul, argumentând că închirierea unei capacități „suverane” construită pe hardware străin poate crea doar o aparență de independență și că decalajul real al Europei este la nivel de cipuri și modele, nu de clădiri. Comisia susține, însă, că infrastructura este un început: finanțatorii publici ar urma să primească o cotă proporțională din puterea de calcul pentru cercetare și proiecte publice, iar pariul este că infrastructura va atrage ulterior talent, startup-uri și, în timp, investiții în producția de cipuri. În acest moment, licitația este deschisă, dar „pachetul” de 30 miliarde euro rămâne în bună măsură o ambiție: UE a anunțat ținta, însă a securizat până acum doar o fracțiune din finanțarea publică necesară. [...]

Marina SUA va folosi un supercomputer Nvidia DGX GB300 pentru a pregăti ofițeri să evalueze limitele și riscurile IA , după ce compania a donat sistemul către Naval Postgraduate School din Monterey, potrivit The Next Web . Miza operațională nu este doar creșterea capacității de calcul, ci formarea unor decidenți care să nu „aibă încredere oarbă” în modele și să știe când tehnologia nu trebuie folosită. Sistemul, descris ca primul supercomputer IA de acest tip din armata americană, rulează pe generația Blackwell Ultra — aceeași linie de cipuri pe care SUA interzice să o vândă către firme chineze. În acest caz, Nvidia a oferit echipamentul gratuit, printr-o donație către fundația școlii, notează publicația, citând o relatare Nextgov . Ce include sistemul și cum va fi folosit DGX GB300 este prezentat ca un sistem integrat (nu un centru de date), care se poate conecta la infrastructura existentă de energie și apă a campusului. Configurația menționată în articol include: 36 procesoare Grace (CPU); 72 plăci grafice Blackwell Ultra (GPU), conectate pentru procesare paralelă. Școala spune că îl va utiliza pentru instruire și aplicații în domenii precum modelare meteo și oceanografică, cercetare operațională, securitate cibernetică și planificare de reziliență. La punerea în funcțiune au contribuit și companii precum Vertiv, DDN și VAST Data. De ce contează: accent pe „judecată”, nu pe „putere de foc” În articol, Naval Postgraduate School își definește explicit obiectivul ca fiind educarea viitorilor lideri militari să înțeleagă suficient de bine aceste tehnologii încât să le poată evalua limitele și să le aplice „etic” și „responsabil”. Căpitanul Michael Owen, vice-provost al Marinei, este citat astfel: „Întrebarea nu este dacă aceste tehnologii vor exista, ci dacă viitorii lideri militari le înțeleg suficient de bine încât să le evalueze limitările, să le aplice etic și să le folosească responsabil.” Dincolo de utilizările academice, donația are și o componentă strategică: un cip considerat prea sensibil pentru export către China ajunge instrument de instruire pentru ofițeri americani, iar Nvidia își expune, în același timp, hardware-ul orientat către zona militară. Context: parteneriat început în 2024 Supercomputerul se bazează pe un acord de cercetare între Nvidia și școală, semnat în decembrie 2024. Potrivit articolului, colaborarea a dus deja la un AI Tech Center în 2025, echipat cu cipuri Blackwell, dispozitive Jetson și platforma de simulare Omniverse. În ansamblu, mesajul instituției este că valoarea principală a noii infrastructuri nu stă doar în capacitatea de calcul, ci în antrenarea discernământului: când și în ce condiții cele mai avansate sisteme de IA nu ar trebui considerate de încredere. [...]

Jensen Huang susține că panica privind dispariția masivă a locurilor de muncă din cauza AI este „o prostie totală” și avertizează că riscul real pentru angajați vine din competiția cu cei care folosesc deja aceste instrumente, potrivit The Next Web . Într-un interviu amplu acordat Axios, șeful Nvidia a respins două idei pe care le vede drept exagerări: că inteligența artificială „va pune capăt omenirii” și că va elimina jumătate dintre joburile din SUA. Huang spune că „toate dovezile” indică „exact opusul”, însă argumentul lui nu este că munca nu se schimbă, ci că oamenii confundă „o sarcină” cu „un job”. „Sarcina” se automatizează, „jobul” se redefinește Huang folosește exemplul radiologilor: citirea scanărilor este o sarcină pe care AI o poate face în mare parte, dar jobul ar rămâne legat de reducerea suferinței și ghidarea pacienților. În aceeași logică, el admite că munca din call-center este „foarte probabil” să fie puternic automatizată, însă consideră că judecata și decizia rămân umane. Pentru a-și susține poziția, Huang invocă și câteva cifre (prezentate ca afirmații ale sale în interviu): numărul radiologilor ar fi în creștere cu aproximativ 20%, deoarece AI le permite să vadă mai mulți pacienți; numărul paralegalilor ar fi în creștere cu circa 10%; joburile din manufactură ar fi crescut cu aproximativ 50% în ultimii ani, pe fondul cursei pentru construirea de centre de date. Mesajul său, formulat direct, mută discuția de la „AI îți ia jobul” la competiția între oameni: „AI nu o să ne distrugă toate joburile. Cineva care folosește AI o să-ți ia jobul.” Miza pentru companii: productivitate și presiune pe recalificare Din perspectiva impactului economic și operațional, poziția lui Huang sugerează că firmele care integrează rapid AI pot obține un avantaj de productivitate, iar cele care întârzie riscă să piardă competitivitate. În același timp, angajații sunt împinși spre adaptare: dacă automatizarea „taie” sarcini, valoarea se mută către activități care cer decizie, relaționare și responsabilitate profesională. Țintă către „doomeri” și un avertisment pentru Washington Huang a criticat și narativele apocaliptice promovate, în opinia lui, de lideri din industrie care „petrec prea mult timp teoretizând” scenarii de tip science-fiction, pentru că „îi face să pară inteligenți”. El spune că discuțiile despre singularitate, simulare sau conștiință a mașinilor sunt „inventate” și că, deși e legitim „să avertizezi oamenii”, este „absolut nepotrivit să inventezi lucruri”. În relația cu factorii de decizie, Huang avertizează că politicienii pot „supra-corecta” dacă „cad în plasa acestor narațiuni”. În același registru, el le-ar fi recomandat administrației Trump să discute cu mulți oameni de știință, nu cu „unul sau doi”, și a respins ideea ca guvernul să ia o participație în Nvidia, pe care o consideră „inutilă”. Context: optimismul lui Huang și interesul Nvidia Huang își proiectează o viziune puternic optimistă: se așteaptă la „un trilion” de agenți AI care rulează simultan și spune că „momentul ChatGPT” pentru roboți a sosit deja, cu mașini utile posibil la 3–4 ani distanță. Acceptă că o bulă AI „va veni într-o zi”, dar „nu azi” și probabil nu în următorii cinci ani. The Next Web notează însă și interesul evident al Nvidia: mai mult AI înseamnă cerere mai mare pentru cipurile companiei. În plus, rivali precum Dario Amodei (Anthropic) ar prognoza contrariul în privința efectelor asupra joburilor. În acest cadru, distincția lui Huang între „sarcină” și „job” rămâne, totuși, nucleul argumentului: automatizarea schimbă munca, dar nu o anulează — iar riscul imediat este competiția cu cei care folosesc AI mai bine și mai repede. [...]
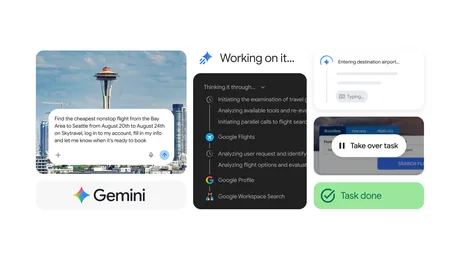
Gemini Spark primește integrare directă cu Chrome , ceea ce îi permite să folosească (cu acordul utilizatorului) conturile autentificate și parolele salvate pentru a automatiza sarcini pe web , potrivit Google Blog . Funcția vizează „comisioane” online mai complexe — de la programarea unor vizionări pentru apartamente salvate până la căutarea opțiunilor de zbor și inițierea procesului de rezervare — dar păstrează utilizatorul în control pentru acțiuni sensibile, precum plățile. Integrarea cu Chrome extinde capabilitățile de navigare ale Spark prin acces la sesiunea de autentificare din browser, ceea ce poate reduce pașii manuali în fluxuri care, în mod normal, cer completări repetate și logări. Google precizează că aceste acțiuni se fac „cu permisiunea” utilizatorului și că, pentru operațiuni sensibile, sarcina este returnată utilizatorului pentru confirmare și finalizare. Securitate și limitări de lansare Google menționează că noua funcționalitate este construită cu protecții împotriva unor amenințări precum „prompt injection” (o tehnică prin care un atacator încearcă să manipuleze instrucțiunile unui model de inteligență artificială pentru a-l determina să execute acțiuni nedorite). În același timp, compania subliniază că utilizatorul rămâne „în buclă” pentru decizii critice, în special cele legate de plăți. Capabilitățile de „auto browse” prin Chrome sunt, în primă fază, în curs de lansare în SUA, cu planuri de extindere în alte regiuni ulterior. Google nu oferă un calendar pentru extinderea internațională. Extinderea accesului: peste 160 de țări, pentru abonații Google AI Pro Separat de integrarea cu Chrome, Google anunță extinderea accesului la Spark pentru abonații Google AI Pro în „peste 160 de țări” suplimentare, începând de astăzi. Miza operațională este creșterea bazei de utilizatori care pot folosi Spark pentru automatizarea sarcinilor zilnice, însă articolul nu detaliază ce piețe sunt incluse sau dacă există diferențe de funcționalitate între regiuni. Pentru lista țărilor, Google indică o pagină de suport. [...]

Amazon își restrânge portofoliul intern de modele Nova pentru a concentra bugetul și puterea de calcul pe un singur „foundation model” competitiv , potrivit The Next Web . Mișcarea are un impact operațional direct: majoritatea produselor Nova intră în regim de întreținere („keep the lights on”), rămânând suportate pentru clienții existenți, dar fără a mai fi o prioritate de dezvoltare. Publicația notează, citând o informație apărută inițial în Business Insider, că Amazon a început să deprecieze (să scoată treptat din uz) o parte importantă din linia Nova, inclusiv modelele de vârf Premier și Omni, generatorul video Reel și generatorul de imagini Canvas. În interior, unii angajați ar descrie situația drept „KTLO”, adică menținerea funcționării fără investiții semnificative în evoluție. Pariul se mută pe „Frontier Model Research” și un debut așteptat la re:Invent Resursele se reorientează către un efort numit Frontier Model Research (FMR), condus de Pieter Abbeel , intrat în Amazon odată cu achiziția din 2024 a startup-ului de robotică Covariant. Un nou model „fanion” este așteptat să fie prezentat la conferința Amazon re:Invent din această toamnă, potrivit Reuters, iar acesta ar putea păstra numele Nova. Schimbarea de direcție este pusă în contextul reorganizării conducerii: după ce, sub fostul șef AI Rohit Prasad, compania a împărțit efortul între modele de text, imagine și video, Peter DeSantis (care a preluat grupul consolidat în decembrie) ar fi concentrat talentul și capacitatea de calcul pe mai puține pariuri „frontier” (modele de vârf). Prasad a plecat la finalul lui 2025, iar fondatorul AGI Lab, David Luan, a plecat în februarie, mai arată articolul. Ce rămâne din Nova și ce se închide Nova nu dispare complet. Amazon ar păstra în portofoliu: Nova 2 Lite Nova 2 Sonic serviciul de personalizare Nova Forge instrumentul de agenți Nova Act În paralel, site-ul AGI din San Francisco – un grup de cercetare de 80 de persoane – a fost închis, potrivit GeekWire. De ce contează: Amazon își joacă diferențiatorul pe infrastructură, nu pe „brandul” de model The Next Web subliniază că Amazon nu a reușit să transforme Nova într-un nume „de masă” comparabil cu OpenAI, Anthropic sau Google, iar sistemele sale s-au dovedit costisitoare de rulat raportat la valoarea livrată. Presiunea a crescut și din partea rivalilor mai ieftini, într-un context mai larg de orientare către modele cu cost redus. În schimb, Amazon își consolidează avantajul tradițional: infrastructura. AWS găzduiește o parte importantă din industrie, cu angajamente de capacitate de calcul de 138 miliarde dolari (aprox. 621 miliarde lei) din partea OpenAI și peste 100 miliarde dolari (aprox. 450 miliarde lei) din partea Anthropic, iar cipurile proprii Trainium au devenit o afacere de ordinul miliardelor de dolari, pe care Jeff Bezos o numește un al patrulea pilon al companiei. Un purtător de cuvânt al Amazon respinge ideea unei retrageri, afirmând că modelele AI rămân printre cele mai importante priorități și că portofoliul este ajustat continuu în funcție de nevoile clienților. Miza imediată se mută la re:Invent: dacă Amazon poate trece de la rolul de „gazdă” și furnizor de cipuri pentru modelele altora la construirea unui model de vârf pe care dezvoltatorii să îl aleagă în mod activ în fața Claude, Gemini sau GPT. [...]
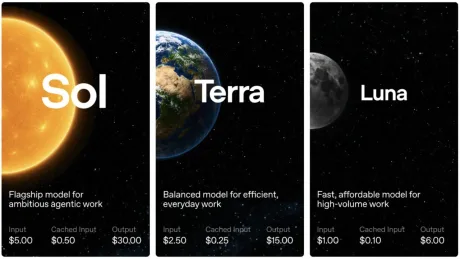
OpenAI taie agresiv costurile de utilizare pentru două modele, într-o mișcare cu impact direct asupra bugetelor de AI ale companiilor. Potrivit Neowin , OpenAI reduce prețurile pentru GPT-5.6 Luna cu 80% și pentru Terra cu 20%, pe fondul competiției tot mai dure cu modele dezvoltate în China. Reducerea de preț este relevantă în primul rând economic: pentru firmele care rulează aplicații bazate pe modele mari de limbaj, costul per utilizare (sau per volum de procesare) este adesea principalul factor care decide ce model ajunge în producție. O ieftinire de 80% la un model poate schimba rapid calculele de rentabilitate și poate accelera migrarea sau extinderea unor proiecte. Ce se schimbă: două reduceri, două niveluri de presiune pe piață Conform informațiilor din sursă, OpenAI aplică: o reducere de 80% pentru GPT-5.6 Luna ; o reducere de 20% pentru Terra . Neowin le plasează explicit în contextul concurenței cu „modelele chinezești”, ceea ce sugerează o strategie de apărare a cotei de piață prin preț, nu doar prin performanță. De ce contează pentru companii: costul devine armă competitivă În practică, astfel de ajustări pot avea câteva efecte imediate în piață: scăderea costului total pentru produse care folosesc AI la scară (asistenți, suport clienți, analiză de documente); presiune pe furnizorii alternativi (inclusiv cei din China) să răspundă cu reduceri sau pachete mai avantajoase; recalibrarea achizițiilor : echipele de produs și IT pot reevalua ce model folosesc, dacă diferența de preț depășește diferențele de calitate percepute. Sursa nu oferă detalii suplimentare despre noile tarife efective sau despre momentul exact al aplicării lor, dincolo de anunțul reducerilor procentuale. [...]

